BERT
2020 年 3 月 11 日新:更小的 BERT 模型
这是在 Well-Read Students Learn Better: On the Importance of Pre-training Compact Models 中引用的 24 个较小的 BERT 模型(仅英文,不加大小写,使用 WordPiece 掩码训练)的版本。
我们已经证明,标准 BERT 配方(包括模型架构和训练目标)在各种模型大小上都有效,除了 BERT-Base 和 BERT-Large。较小的 BERT 模型适用于计算资源受限的环境。它们可以以与原始 BERT 模型相同的方式进行微调。然而,它们在知识提炼的背景下最为有效,其中微调标签由更大、更准确的教师生成。
我们的目标是在计算资源较少的机构中进行研究,并鼓励社区寻求创新方向来替代增加模型容量。
您可以从此处下载所有 24 个,也可以从下表中单独下载:
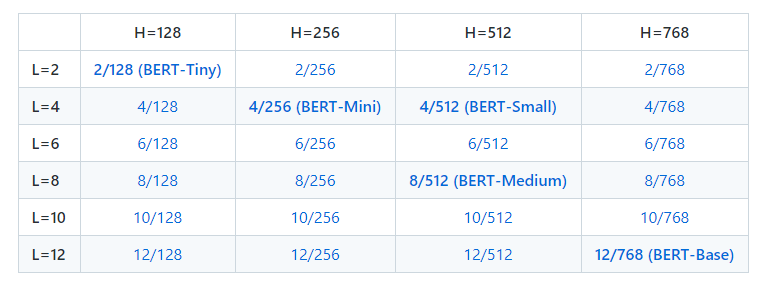
请注意,包含此版本中的 BERT-Base 模型只是为了完整性; 它在与原始模型相同的机制下进行了重新训练。
以下是测试集上对应的 GLUE 分数:
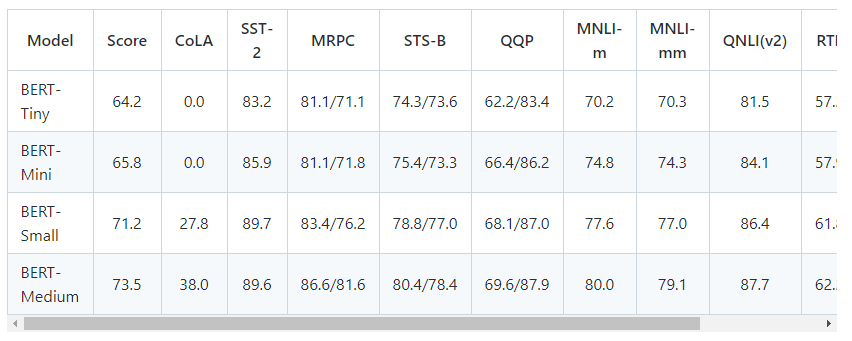
对于每个任务,我们从下面的列表中选择了最好的微调超参数,并训练了 4 个 epoch:
批量大小:8、16、32、64、128
学习率:3e-4、1e-4、5e-5、3e-5
如果您使用这些模型,请引用以下论文:
@article{turc2019,
标题={阅读良好的学生学得更好:关于预训练紧凑模型的重要性},
作者={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv 预印本 arXiv:1908.08962v2 },
年={2019}
}
2019 年 5 月 31 日新:全词掩蔽模型
这是几个新模型的发布,这些模型是改进预处理代码的结果。
在原始的预处理代码中,我们随机选择 WordPiece 标记进行掩码。例如:
输入文本:这个人跳起来,把他的篮子放在 phil ##am ##mon 的头上 原始蒙面输入:[MASK] man [MASK] up , put his [MASK] on phil [MASK] ##mon ‘s头
这项新技术被称为全字掩码。在这种情况下,我们总是同时屏蔽与一个单词对应的所有标记。总体掩蔽率保持不变。
Whole Word Masked Input: man [MASK] up , put his basket on [MASK] [MASK] [MASK]’s head
训练是相同的——我们仍然独立地预测每个掩码的 WordPiece 标记。改进来自这样一个事实,即原始预测任务对于已拆分为多个 WordPieces 的单词来说太“容易”了。
这可以在数据生成期间通过将标志 –do_whole_word_mask=True 传递给 create_pretraining_data.py 来启用。
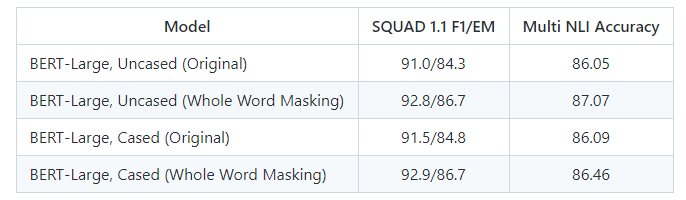
带有全字掩码的预训练模型链接如下。数据和训练在其他方面是相同的,并且模型具有与原始模型相同的结构和词汇。我们只包括 BERT-Large 模型。使用这些模型时,请在论文中明确说明您使用的是 BERT-Large 的 Whole Word Masking 变体。
2019 年 2 月 7 日新功能:TfHub 模块
BERT 已上传到 TensorFlow Hub。有关如何使用 TF Hub 模块的示例,请参阅 run_classifier_with_tfhub.py,或在 Colab 上的浏览器中运行示例。
2018 年 11 月 23 日新增:非标准化多语言模型 + 泰语 + 蒙古语
我们上传了一个新的多语言模型,它不对输入执行任何规范化(没有小写、重音剥离或 Unicode 规范化),还包括泰语和蒙古语。
建议使用此版本开发多语言模型,尤其是非拉丁字母的语言。
这不需要任何代码更改,可以在这里下载:
BERT-Base, Multilingual Cased:104 种语言,12 层,768 隐藏,12 头,110M 参数
2018 年 11 月 15 日新:SOTA SQuAD 2.0 系统
我们发布了代码更改以重现我们 83% 的 F1 SQuAD 2.0 系统,该系统目前以 3% 的优势在排行榜上排名第一。有关详细信息,请参阅 README 的 SQuAD 2.0 部分。
2018 年 11 月 5 日新:提供第三方 PyTorch 和 Chainer 版本的 BERT
HuggingFace 的 NLP 研究人员提供了一个 PyTorch 版本的 BERT,它与我们预训练的检查点兼容,并且能够重现我们的结果。 Sosuke Kobayashi 还提供了 BERT 的 Chainer 版本(谢谢!)我们没有参与 PyTorch 实现的创建或维护,因此请向该存储库的作者提出任何问题。
2018 年 11 月 3 日新功能:提供多语言和中文模式
我们提供了两种新的 BERT 模型:
BERT-Base, Multilingual(不推荐,使用 Multilingual Cased 代替):102 种语言,12 层,768 隐藏,12 头,110M 参数
BERT-Base,中文:中文简繁体,12层,768隐藏,12头,110M参数
我们对中文使用基于字符的标记化,对所有其他语言使用 WordPiece 标记化。两种模型都应该开箱即用,无需更改任何代码。我们确实在 tokenization.py 中更新了 BasicTokenizer 的实现以支持汉字标记化,所以如果你分叉了它,请更新。但是,我们没有更改标记化 API。
有关更多信息,请参阅多语言自述文件。
结束新信息
简介
BERT,或 Transformers 的双向编码器表示,是一种预训练语言表示的新方法,它在各种自然语言处理 (NLP) 任务中获得最先进的结果。
我们的学术论文详细描述了 BERT,并提供了多项任务的完整结果,可以在这里找到:https://arxiv.org/abs/1810.04805。
举几个数字,以下是 SQuAD v1.1 问答任务的结果:
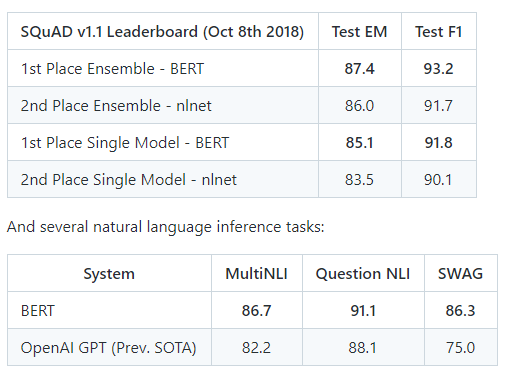
加上许多其他任务。
此外,这些结果都是在几乎没有特定任务的神经网络架构设计的情况下获得的。
如果您已经知道 BERT 是什么并且只想开始,您可以下载预训练模型并在几分钟内运行最先进的微调。
什么是 BERT?
BERT 是一种预训练语言表示的方法,这意味着我们在大型文本语料库(如维基百科)上训练一个通用的“语言理解”模型,然后将该模型用于我们关心的下游 NLP 任务(如问题回答)。 BERT 优于以前的方法,因为它是第一个用于预训练 NLP 的无监督、深度双向系统。
无监督意味着 BERT 仅使用纯文本语料库进行训练,这很重要,因为大量纯文本数据在网络上以多种语言公开可用。
预训练的表示也可以是无上下文的或上下文的,上下文表示还可以是单向的或双向的。 word2vec 或 GloVe 等上下文无关模型为词汇表中的每个单词生成单个“词嵌入”表示,因此 bank 在银行存款和河岸中具有相同的表示。相反,上下文模型会根据句子中的其他单词生成每个单词的表示。
BERT 建立在最近在预训练上下文表示方面的工作之上——包括半监督序列学习、生成预训练、ELMo 和 ULMFit——但至关重要的是,这些模型都是单向或浅双向的。这意味着每个单词仅使用其左侧(或右侧)的单词进行上下文化。例如,在句子 I made a bank deposit 中,bank 的单向表示仅基于 I made a but not deposit。以前的一些工作确实结合了来自单独的左上下文和右上下文模型的表示,但只是以“浅”的方式。 BERT 使用其左右上下文来表示“银行”——我做了一笔存款——从深度神经网络的最底层开始,因此它是深度双向的。
BERT 为此使用了一种简单的方法:我们屏蔽掉输入中 15% 的单词,通过深度双向 Transformer 编码器运行整个序列,然后仅预测被屏蔽的单词。例如:
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
为了学习句子之间的关系,我们还训练了一个可以从任何单语语料库生成的简单任务:给定两个句子 A 和 B,B 是 A 之后的实际下一个句子,还是只是语料库中的一个随机句子 ?
Sentence A: the man went to the store .
Sentence B: he bought a gallon of milk .
Label: IsNextSentence
Sentence A: the man went to the store .
Sentence B: penguins are flightless .
Label: NotNextSentence
然后我们在大型语料库(Wikipedia + BookCorpus)上长时间(1M 更新步骤)训练一个大型模型(12 层到 24 层 Transformer),这就是 BERT。
使用 BERT 有两个阶段:预训练和微调。
预训练相当昂贵(在 4 到 16 个 Cloud TPU 上需要 4 天),但对于每种语言都是一次性的(当前模型仅支持英语,但多语言模型将在不久的将来发布)。我们正在从论文中发布一些在 Google 进行预训练的预训练模型。大多数 NLP 研究人员永远不需要从头开始预训练他们自己的模型。
微调成本低。从完全相同的预训练模型开始,论文中的所有结果最多可以在单个 Cloud TPU 上复制 1 小时,或者在 GPU 上复制几个小时。例如,可以在单个 Cloud TPU 上对 SQuAD 进行大约 30 分钟的训练,以达到 91.0% 的 Dev F1 分数,这是最先进的单个系统。
BERT 的另一个重要方面是它可以很容易地适应多种类型的 NLP 任务。在本文中,我们展示了句子级别(例如,SST-2)、句子对级别(例如,MultiNLI)、单词级别(例如,NER)和跨度级别的最新结果(例如,SQuAD)任务,几乎没有针对特定任务的修改。
此存储库中发布了什么?
我们正在发布以下内容:
BERT 模型架构(主要是标准的 Transformer 架构)的 TensorFlow 代码。
论文中 BERT-Base 和 BERT-Large 的小写和大写版本的预训练检查点。
TensorFlow 代码用于一键复制论文中最重要的微调实验,包括 SQuAD、MultiNLI 和 MRPC。
此存储库中的所有代码都可与 CPU、GPU 和 Cloud TPU 一起使用。
预训练模型
我们正在发布论文中的 BERT-Base 和 BERT-Large 模型。 Uncased 表示文本在 WordPiece 标记化之前已小写,例如,John Smith 变为 john smith。 Uncased 模型还去掉了任何重音标记。大小写意味着保留真实的大小写和重音标记。通常,除非您知道案例信息对您的任务很重要(例如,命名实体识别或词性标记),否则 Uncased 模型会更好。
这些模型都是在与源代码 (Apache 2.0) 相同的许可下发布的。
有关多语言和中文模型的信息,请参阅多语言自述文件。
使用案例模型时,请确保将 –do_lower=False 传递给训练脚本。 (或者如果您使用自己的脚本,则直接将 do_lower_case=False 传递给 FullTokenizer。)
模型的链接在这里(右键单击名称上的“将链接另存为…”):
BERT-Large, Uncased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Large, Cased (Whole Word Masking): 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Uncased: 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Large, Uncased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Cased: 12-layer, 768-hidden, 12-heads , 110M parametersBERT-Large, Cased: 24-layer, 1024-hidden, 16-heads, 340M parametersBERT-Base, Multilingual Cased (New, recommended): 104 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Multilingual Uncased (Orig, not recommended) (Not recommended, use Multilingual Casedinstead): 102 languages, 12-layer, 768-hidden, 12-heads, 110M parametersBERT-Base, Chinese: Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
每个 .zip 文件包含三个项目:
包含预训练权重(实际上是 3 个文件)的 TensorFlow 检查点 (bert_model.ckpt)。
用于将 WordPiece 映射到单词 id 的词汇文件 (vocab.txt)。
一个配置文件 (bert_config.json),它指定模型的超参数。
使用 BERT 进行微调
重要提示:本文中的所有结果均在具有 64GB RAM 的单个 Cloud TPU 上进行了微调。目前无法使用具有 12GB – 16GB RAM 的 GPU 在纸上重新生成大部分 BERT-Large 结果,因为内存中可以容纳的最大批大小太小。我们正在努力将代码添加到此存储库,以允许在 GPU 上实现更大的有效批量大小。有关更多详细信息,请参阅有关内存不足问题的部分。
此代码已使用 TensorFlow 1.11.0 进行了测试。它使用 Python2 和 Python3 进行了测试(但更彻底地使用了 Python2,因为这是 Google 内部使用的)。
使用 BERT-Base 的微调示例应该能够使用给定的超参数在具有至少 12GB RAM 的 GPU 上运行。
使用 Cloud TPU 进行微调
下面的大多数示例都假设您将使用 Titan X 或 GTX 1080 等 GPU 在本地机器上运行训练/评估。
但是,如果您有权访问要训练的 Cloud TPU,只需将以下标志添加到 run_classifier.py 或 run_squad.py:
--use_tpu=True \
--tpu_name=$TPU_NAME
请参阅 Google Cloud TPU 教程,了解如何使用 Cloud TPU。或者,您可以使用 Google Colab 笔记本“BERT FineTuning with Cloud TPUs”。
在 Cloud TPU 上,预训练模型和输出目录需要位于 Google Cloud Storage 上。例如,如果您有一个名为 some_bucket 的存储桶,则可以改用以下标志:
–output_dir=gs://some_bucket/my_output_dir/
解压后的预训练模型文件也可以在 Google Cloud Storage 文件夹 gs://bert_models/2018_10_18 中找到。例如:
导出 BERT_BASE_DIR=gs://bert_models/2018_10_18/uncased_L-12_H-768_A-12
句子(和句子对)分类任务
在运行此示例之前,您必须通过运行此脚本下载 GLUE 数据并将其解压缩到某个目录 $GLUE_DIR。接下来,下载 BERT-Base 检查点并将其解压缩到某个目录 $BERT_BASE_DIR。
此示例代码在 Microsoft Research Paraphrase Corpus (MRPC) 语料库上对 BERT-Base 进行微调,该语料库仅包含 3,600 个示例,并且可以在大多数 GPU 上在几分钟内进行微调。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
你应该看到这样的输出:
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
这意味着开发集准确率为 84.55%。即使从相同的预训练检查点开始,像 MRPC 这样的小集在 Dev 集的准确性上也有很大的差异。如果您重新运行多次(确保指向不同的 output_dir),您应该会看到 84% 到 88% 之间的结果。
其他一些预训练模型在 run_classifier.py 中现成实现,因此按照这些示例将 BERT 用于任何单句或句子对分类任务应该很简单。
注意:您可能会看到一条消息正在 CPU 上运行火车。这实际上只是意味着它运行在包含 GPU 的 Cloud TPU 以外的其他东西上。
分类器的预测
训练好分类器后,您可以使用 –do_predict=true 命令在推理模式下使用它。您需要在输入文件夹中有一个名为 test.tsv 的文件。输出将在输出文件夹中名为 test_results.tsv 的文件中创建。每行将包含每个样本的输出,列是类概率。
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
export GLUE_DIR=/path/to/glue
export TRAINED_CLASSIFIER=/path/to/fine/tuned/classifier
python run_classifier.py \
--task_name=MRPC \
--do_predict=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$TRAINED_CLASSIFIER \
--max_seq_length=128 \
--output_dir=/tmp/mrpc_output/
SQuAD 1.1
斯坦福问答数据集 (SQuAD) 是一个流行的问答基准数据集。 BERT(在发布时)在 SQuAD 上获得了最先进的结果,几乎没有针对特定任务的网络架构修改或数据增强。 然而,它确实需要半复杂的数据预处理和后处理来处理(a)SQuAD 上下文段落的可变长度性质,以及(b)用于 SQuAD 训练的字符级答案注释。 此处理在 run_squad.py 中实现和记录。
要在 SQuAD 上运行,您首先需要下载数据集。 SQuAD 网站似乎不再链接到 v1.1 数据集,但可以在此处找到必要的文件:
将这些下载到某个目录 $SQUAD_DIR。
由于内存限制,论文中最先进的 SQuAD 结果目前无法在 12GB-16GB GPU 上重现(事实上,即使批量大小 1 似乎也不适合使用 BERT-Large 的 12GB GPU)。 但是,可以使用以下超参数在 GPU 上训练一个相当强大的 BERT-Base 模型:
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=12 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=/tmp/squad_base/
开发集预测将保存到 output_dir 中名为 predictions.json 的文件中:
python $SQUAD_DIR/evaluate-v1.1.py $SQUAD_DIR/dev-v1.1.json ./squad/predictions.json
{"f1": 88.41249612335034, "exact_match": 81.2488174077578}
您应该会看到类似于论文中报告的 BERT-Base 的 88.5% 的结果。
如果您可以访问 Cloud TPU,则可以使用 BERT-Large 进行训练。 这是一组超参数(与论文略有不同),它们始终获得大约 90.5%-91.0% 仅在 SQuAD 上训练的 F1 单系统:
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v1.1.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v1.1.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME
例如,使用这些参数进行一次随机运行会产生以下 Dev 分数:
{"f1": 90.87081895814865, "exact_match": 84.38978240302744}
如果您在此之前在 TriviaQA 上微调一个 epoch,结果会更好,但您需要将 TriviaQA 转换为 SQuAD json 格式。
SQuAD 2.0
该模型也在 run_squad.py 中实现和记录。
要在 SQuAD 2.0 上运行,您首先需要下载数据集。 必要的文件可以在这里找到:
将这些下载到某个目录 $SQUAD_DIR。
在 Cloud TPU 上,您可以使用 BERT-Large 运行,如下所示:
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v2.0.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME \
--version_2_with_negative=True
我们假设您已将从输出目录复制到名为的本地目录。/ squad/。 初始DEV SET预测将在./squad/predictions.json和每个问题的最佳答案(“”)和最佳非空答案之间的差异将在文件中。/ squad/null_odds.json
运行此脚本以调整预测NULL与非空答案的阈值:
python $ squad_dir / evaluate-v2.0.py $ squad_dir / dev-v2.0.json ./squad/predictions.json – prob-file ./squad/null_odds.json
假设脚本输出“best_f1_thresh”阈值。 (典型值在-1.0和-5.0之间)。 您现在可以重新运行模型以使用派生阈值生成预测,或者您可以从。/squad/nbest_predictions.json提取适当的答案。
python run_squad.py \
--vocab_file=$BERT_LARGE_DIR/vocab.txt \
--bert_config_file=$BERT_LARGE_DIR/bert_config.json \
--init_checkpoint=$BERT_LARGE_DIR/bert_model.ckpt \
--do_train=False \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict_file=$SQUAD_DIR/dev-v2.0.json \
--train_batch_size=24 \
--learning_rate=3e-5 \
--num_train_epochs=2.0 \
--max_seq_length=384 \
--doc_stride=128 \
--output_dir=gs://some_bucket/squad_large/ \
--use_tpu=True \
--tpu_name=$TPU_NAME \
--version_2_with_negative=True \
--null_score_diff_threshold=$THRESH
内存溢出的问题
本文中的所有实验都在云TPU上进行微调,具有64GB的设备RAM。因此,使用带12GB – 16GB的RAM的GPU时,如果使用纸纸中描述的相同的超参数,则可能会遇到内存中的问题。
影响内存使用的因素是:
max_seq_length:发布的模型培训,序列长度高达512,但您可以使用较短的最大序列长度进行微调,以节省大量内存。这由我们的示例代码中的max_seq_length标志控制。
TRAIN_BATCH_SIZE:内存使用率也与批处理大小成比例。
模型类型,BERT-BASE与BERT-LIGHT:BERT-MATRIC型号比BERT基本要显着更多的内存。
优化器:BERT的默认优化器是ADAM,这需要大量额外的内存来存储M和V向量。切换到更多内存高效的优化器可以减少内存使用情况,但也可以影响结果。我们没有尝试使用其他优化器进行微调。
使用默认的培训脚本(run_classifier.py和run_squad.py),我们通过Tensorflow 1.11.0基准于 Titan X GPU (12GB RAM)上的最大批量大小:
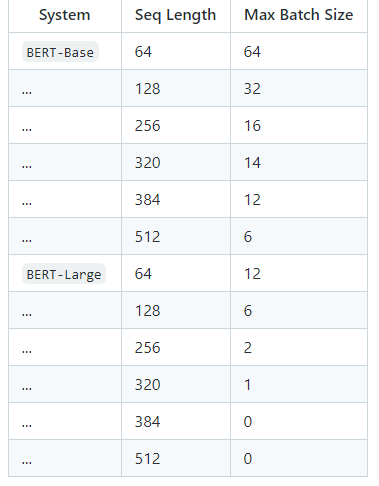
不幸的是,BERT-Large 的这些最大批量大小非常小,以至于无论使用何种学习率,它们实际上都会损害模型的准确性。我们正在努力向这个存储库添加代码,这将允许在 GPU 上使用更大的有效批量大小。该代码将基于以下一种(或两种)技术:
梯度累积:小批量中的样本通常独立于梯度计算(不包括批量归一化,此处未使用)。这意味着可以在执行权重更新之前累积多个较小 minibatch 的梯度,这将完全等同于单个较大的更新。
梯度检查点:在 DNN 训练期间 GPU/TPU 内存的主要用途是缓存正向传递中的中间激活,这是反向传递中高效计算所必需的。 “梯度检查点”通过以智能方式重新计算激活来用内存换取计算时间。
但是,这在当前版本中没有实现。
使用 BERT 提取固定特征向量(如 ELMo)
在某些情况下,与其对整个预训练模型进行端到端微调,不如获得预训练的上下文嵌入,这是从预训练的隐藏层生成的每个输入标记的固定上下文表示。 – 训练模型。这也应该可以缓解大多数内存不足的问题。
例如,我们包含脚本 extract_features.py 可以像这样使用:
# Sentence A and Sentence B are separated by the ||| delimiter for sentence
# pair tasks like question answering and entailment.
# For single sentence inputs, put one sentence per line and DON'T use the
# delimiter.
echo 'Who was Jim Henson ? ||| Jim Henson was a puppeteer' > /tmp/input.txt
python extract_features.py \
--input_file=/tmp/input.txt \
--output_file=/tmp/output.jsonl \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--layers=-1,-2,-3,-4 \
--max_seq_length=128 \
--batch_size=8
这将创建一个 JSON 文件(每行输入一行),其中包含来自层指定的每个 Transformer 层的 BERT 激活(-1 是 Transformer 的最终隐藏层等)
请注意,此脚本将生成非常大的输出文件(默认情况下,每个输入标记大约 15kb)。
如果您需要保持原始单词和标记化单词之间的对齐(用于投影训练标签),请参阅下面的标记化部分。
注意:您可能会看到一条消息,例如在 model_dir: /tmp/tmpuB5g5c 中找不到训练好的模型,正在运行初始化以进行预测。此消息是预期的,它只是意味着我们使用的是 init_from_checkpoint() API,而不是保存的模型 API。如果您没有指定检查点或指定无效的检查点,此脚本会报错。
代币化
对于句子级任务(或句子对)任务,标记化非常简单。只需按照 run_classifier.py 和 extract_features.py 中的示例代码进行操作即可。句子级任务的基本过程是:
实例化 tokenizer = tokenization.FullTokenizer 的实例
使用 tokens = tokenizer.tokenize(raw_text) 对原始文本进行标记。
截断到最大序列长度。 (您最多可以使用 512,但出于内存和速度原因,您可能希望使用更短的时间。)
在正确的位置添加 [CLS] 和 [SEP] 令牌。
单词级别和跨度级别的任务(例如,SQuAD 和 NER)更复杂,因为您需要保持输入文本和输出文本之间的对齐,以便您可以投射训练标签。 SQuAD 是一个特别复杂的示例,因为输入标签是基于字符的,并且 SQuAD 段落通常比我们的最大序列长度长。请参阅 run_squad.py 中的代码以显示我们如何处理此问题。
在我们描述处理单词级任务的一般方法之前,了解我们的分词器到底在做什么是很重要的。它有三个主要步骤:
文本规范化:将所有空白字符转换为空格,并且(对于 Uncased 模型)小写输入并去除重音标记。例如,约翰·约翰逊的,→ 约翰·约翰逊的,。
标点拆分:拆分两边的所有标点字符(即在所有标点字符周围添加空格)。标点字符被定义为 (a) 任何具有 P* Unicode 类的字符,(b) 任何非字母/数字/空格的 ASCII 字符(例如,像 $ 这样的字符在技术上不是标点符号)。例如,john johanson’s, → john johanson’s ,
WordPiece 标记化:将空白标记化应用于上述过程的输出,并将 WordPiece 标记化分别应用于每个标记。 (我们的实现直接基于来自 tensor2tensor 的实现,它是链接的)。例如,john johanson’s , → john johan ##son’s ,
这种方案的优点是它与大多数现有的英语分词器“兼容”。例如,假设您有一个词性标注任务,如下所示:
输入: John Johanson 's house
标签: NNP NNP POS NN
标记化的输出将如下所示:
代币:john johan ##son 的房子
至关重要的是,这将与原始文本是 John Johanson 的房子的输出相同(在 ‘s 之前没有空格)。
如果您有一个带有单词级别注释的预标记表示,您可以简单地独立标记每个输入单词,并确定性地保持原始到标记的对齐方式:
### Input
orig_tokens = ["John", "Johanson", "'s", "house"]
labels = ["NNP", "NNP", "POS", "NN"]
### Output
bert_tokens = []
# Token map will be an int -> int mapping between the `orig_tokens` index and
# the `bert_tokens` index.
orig_to_tok_map = []
tokenizer = tokenization.FullTokenizer(
vocab_file=vocab_file, do_lower_case=True)
bert_tokens.append("[CLS]")
for orig_token in orig_tokens:
orig_to_tok_map.append(len(bert_tokens))
bert_tokens.extend(tokenizer.tokenize(orig_token))
bert_tokens.append("[SEP]")
# bert_tokens == ["[CLS]", "john", "johan", "##son", "'", "s", "house", "[SEP]"]
# orig_to_tok_map == [1, 2, 4, 6]
现在 orig_to_tok_map 可用于将标签投影到标记化表示。
有一些常见的英语标记化方案会导致 BERT 的预训练方式略有不匹配。例如,如果您的输入标记化拆分了类似 do n’t 的缩略词,这将导致不匹配。如果可以这样做,您应该预处理您的数据以将它们转换回看起来很原始的文本,但如果不可能,这种不匹配可能不是什么大问题。
使用 BERT 进行预训练
我们正在发布代码来对任意文本语料库进行“蒙面 LM”和“下一句预测”。请注意,这不是论文中使用的确切代码(原始代码是用 C++ 编写的,并且有一些额外的复杂性),但该代码确实会生成论文中描述的预训练数据。
以下是如何运行数据生成。输入是一个纯文本文件,每行一个句子。 (重要的是这些是“下一句预测”任务的实际句子)。文档由空行分隔。输出是一组序列化为 TFRecord 文件格式的 tf.train.Examples。
您可以使用现成的 NLP 工具包(例如 spaCy)执行句子分割。 create_pretraining_data.py 脚本将连接段,直到它们达到最大序列长度,以最大限度地减少填充造成的计算浪费(有关更多详细信息,请参阅脚本)。但是,您可能希望有意在输入数据中添加少量噪声(例如,随机截断 2% 的输入段),以使其在微调期间对非句子输入更加稳健。
该脚本将整个输入文件的所有示例存储在内存中,因此对于大型数据文件,您应该对输入文件进行分片并多次调用该脚本。 (您可以将文件 glob 传递给 run_pretraining.py,例如 tf_examples.tf_record*。)
max_predictions_per_seq 是每个序列的掩码 LM 预测的最大数量。您应该将其设置为大约 max_seq_length * masked_lm_prob (脚本不会自动执行此操作,因为需要将确切的值传递给两个脚本)。
python create_pretraining_data.py \
--input_file=./sample_text.txt \
--output_file=/tmp/tf_examples.tfrecord \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--do_lower_case=True \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--masked_lm_prob=0.15 \
--random_seed=12345 \
--dupe_factor=5
以下是如何进行预训练。 如果您是从头开始预训练,请不要包含 init_checkpoint。 模型配置(包括词汇大小)在 bert_config_file 中指定。 此演示代码仅对少量步骤 (20) 进行预训练,但实际上您可能希望将 num_train_steps 设置为 10000 步或更多。 传递给 run_pretraining.py 的 max_seq_length 和 max_predictions_per_seq 参数必须与 create_pretraining_data.py 相同。
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
这将产生如下输出:
***** Eval results *****
global_step = 20
loss = 0.0979674
masked_lm_accuracy = 0.985479
masked_lm_loss = 0.0979328
next_sentence_accuracy = 1.0
next_sentence_loss = 3.45724e-05
请注意,由于我们的 sample_text.txt 文件非常小,因此此示例训练将在几个步骤中过度拟合该数据并产生不切实际的高精度数字。
预训练提示和注意事项
如果使用您自己的词汇表,请确保更改 bert_config.json 中的 vocab_size。如果你使用更大的词汇量而不改变这一点,那么在 GPU 或 TPU 上训练时,由于未经检查的越界访问,你可能会得到 NaN。
如果您的任务有大量特定领域的语料库可用(例如,“电影评论”或“科学论文”),那么从 BERT 检查点开始对您的语料库进行额外的预训练步骤可能会有所帮助。
我们在论文中使用的学习率为 1e-4。但是,如果您从现有的 BERT 检查点开始执行额外的预训练步骤,则应使用较小的学习率(例如 2e-5)。
当前的 BERT 模型仅支持英语,但我们确实计划在不久的将来(希望在 2018 年 11 月末)发布一个已在多种语言上进行预训练的多语言模型。
较长的序列成本不成比例,因为注意力与序列长度成二次方。换句话说,一批 64 个长度为 512 的序列比一批 256 个长度为 128 的序列要昂贵得多。全连接/卷积成本相同,但 512 长度序列的注意力成本要高得多.因此,一个好的方法是预先训练 90,000 步,序列长度为 128,然后再进行 10,000 步,序列长度为 512。学习位置嵌入通常需要非常长的序列,这可以学得还算快。请注意,这确实需要使用不同的 max_seq_length 值生成两次数据。
如果您是从头开始进行预训练,请准备好预训练的计算成本很高,尤其是在 GPU 上。如果您是从头开始进行预训练,我们推荐的方法是在单个可抢占 Cloud TPU v2 上预训练 BERT-Base,这需要大约 2 周时间,成本约为 500 美元(基于 2018 年 10 月的定价) .与论文中使用的相比,仅在单个 Cloud TPU 上进行训练时,您将不得不缩小批量大小。建议使用适合 TPU 内存的最大批量大小。
预训练数据
我们将无法发布论文中使用的预处理数据集。对于 Wikipedia,推荐的预处理是下载最新的转储,使用 WikiExtractor.py 提取文本,然后应用任何必要的清理将其转换为纯文本。
不幸的是,收集 BookCorpus 的研究人员不再提供公开下载。 Project Guttenberg 数据集是一个较小的(2 亿字)公共领域的旧书集合。
Common Crawl 是另一个非常大的文本集合,但您可能需要进行大量的预处理和清理以提取可用的语料库以用于预训练 BERT。
学习一个新的 WordPiece 词汇
此存储库不包含用于学习新 WordPiece 词汇的代码。原因是论文中使用的代码是用 C++ 实现的,依赖于 Google 的内部库。对于英语,从我们的词汇和预训练模型开始几乎总是更好。对于学习其他语言的词汇,有许多可用的开源选项。但是,请记住,这些与我们的 tokenization.py 库不兼容:
在 Colab 中使用 BERT
如果您想将 BERT 与 Colab 一起使用,您可以从笔记本“BERT FineTuning with Cloud TPUs”开始。在撰写本文时(2018 年 10 月 31 日),Colab 用户可以完全免费访问 Cloud TPU。注意:每位用户一个,可用性有限,需要一个带有存储空间的 Google Cloud Platform 帐户(尽管注册 GCP 时可以使用免费信用购买存储空间),并且此功能将来可能不再可用。单击刚刚链接的 BERT Colab 以获取更多信息。
常问问题
此代码与 Cloud TPU 兼容吗? GPU 呢?
是的,这个存储库中的所有代码都可以与 CPU、GPU 和 Cloud TPU 一起使用。但是,GPU 训练仅限于单 GPU。
我收到内存不足错误,怎么了?
有关更多信息,请参阅有关内存不足问题的部分。
有可用的 PyTorch 版本吗?
没有官方的 PyTorch 实现。然而,来自 HuggingFace 的 NLP 研究人员提供了一个 PyTorch 版本的 BERT,它与我们预训练的检查点兼容,并且能够重现我们的结果。我们没有参与 PyTorch 实现的创建或维护,因此请向该存储库的作者提出任何问题。
是否有可用的 Chainer 版本?
没有官方的 Chainer 实现。然而,Sosuke Kobayashi 提供了 BERT 的 Chainer 版本,它与我们预先训练的检查点兼容,并且能够重现我们的结果。我们没有参与 Chainer 实现的创建或维护,因此请向该存储库的作者提出任何问题。
是否会发布其他语言的模型?
是的,我们计划在不久的将来发布多语言 BERT 模型。我们无法就将包含哪些语言做出确切承诺,但它可能是一个单一模型,其中包含大多数拥有庞大维基百科的语言。
是否会发布比 BERT-Large 更大的模型?
到目前为止,我们还没有尝试训练任何比 BERT-Large 更大的东西。如果我们能够获得重大改进,我们可能会发布更大的模型。
这个库是在什么许可证下发布的?
所有代码和模型均在 Apache 2.0 许可下发布。有关详细信息,请参阅许可证文件。
我如何引用 BERT?
现在,引用 the Arxiv paper:
@article{devlin2018bert,
title={BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding},
author={Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1810.04805},
year={2018}
}
如果我们将论文提交给会议或期刊,我们将更新 BibTeX。
免责声明
这不是 Google 的官方产品。
联系信息
有关使用 BERT 的帮助或问题,请提交 GitHub 问题。
有关 BERT 的个人交流,请联系 Jacob Devlin (jacobdevlin@google.com)、Ming-Wei Chang (mingweichang@google.com) 或 Kenton Lee (kentonl@google.com)。