BERT 模型的深度揭秘
2018 年,Google 提出了一种特殊的语言表示模型,称为“BERT”,代表“来自 Transformers 的双向编码器表示”。 以前的语言表示模型(例如 OpenAI GPT)使用单向方法(从左到右)来编码序列。 然而,这种方法是有限的,因为上下文只能从一个方向学习。
例如,考虑到这句话——“ The man was looking at the cloudy sky. The man witnessed a cloudy state of mind for the whole day 。” 在这里,无论考虑上下文或句子中单词的实际含义,之前的模型都会产生相同的单词“cloudy”嵌入。 而对于 BERT 模型,“多云”一词将根据不同的上下文具有不同的嵌入。
该模型在现实生活中的主要应用之一是提高对谷歌搜索引擎的查询理解。 早些时候,搜索引擎是基于关键字的,无法考虑可以提出相同问题的各种格式。 因此,在搜索引擎中使用 BERT 有助于显着改善查询结果。
需要注意的重要一点是,BERT 不是一种新的架构设计,而是一种新的训练策略。 由于 BERT 使用了论文中提出的 Transformer 的编码器部分——Attention Is All You Need,我们将花一些时间首先了解相同的内容,然后再讨论 BERT 不同阶段的详细工作。
变换器 – 编码器
1.1 简单多头注意力机制:
Transformer 中使用的最重要的概念是“注意”机制。 让我们看看下面的图片:

当我们第一次看到图像时,我们的大部分注意力都被绿色人物——自由女神像所吸引。
同样,当提供上下文(查询)时,我们不应该对每个输入给予同等的重视,而应该更多地关注一些重要的输入。
在这里,如果查询是关于建筑物的,那么我们的注意力就会放在背景上。
因此,我们将输入一个称为 Z 的新项,而不是普通的原始输入 x 到一个层,这将是所有单个输入 xi 的加权和。
在数学上它表示为,
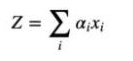
其中 ai 是决定注意力的个体权重。
为了更好地理解注意力的概念,让我们引入以下变量——Q、K、V。Q 代表 Query,这是我们试图查看的上下文,Value 表示给定的输入(像素或文本特征), Key 是 Value 的编码表示。
例如,在上图中,如果:
Query = 绿色
Key=建筑
那么价值将是,

因此,为了形成对输入的注意力,我们需要将查询和键相关联并删除不相关的值。
再次考虑这个例子,
| The man was looking at the cloudy sky 。 (字数 = 8)
由于有 8 个单词,我们将有 8 个查询、8 个键和 8 个值。
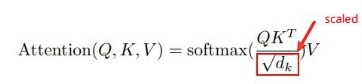
Q = 8X512、K^T = 512X8、V = 8X512 和最后 d_k = 512 的维度。512 是作为输入馈送到编码器的固定维度数。
在等式中,Q 和 K 矩阵之间的点积将导致它们之间的相似度同时生成,而不是单独计算每个单词的相似度。 此外,我们在分母中有一个维度数的平方根,以便缩放完整值。 这将有助于确保顺利进行训练。
刚才我们理解的是简单的注意力,现在让我们继续理解
multi-head 注意力是什么意思?
多头注意力是转换器使用的一项功能,它为每个查询生成 h 个注意力,而不是一个注意力。使用 h attention 的主要原因是为特定查询获得 h 个不同的视角。考虑这么多角度将大大提高模型的整体准确性。对于输出,将所有 h 个注意力连接起来,然后输入到点积方程中。
1.2 跳过连接和层规范化:
编码器的另一个主要组成部分是跳过连接和归一化层。
跳过连接基本上是通过跳过中间的一些层将一层连接到另一层的残差块。引入跳跃连接的想法是解决深度神经网络中的退化问题(梯度消失)。跳过连接有助于网络的最佳训练。
层归一化类似于批量归一化,除了在层归一化中,归一化发生在同一层中的特征上。
下图展示了编码器的结构,展示了multi-head 注意力、跳过连接和层归一化的使用。
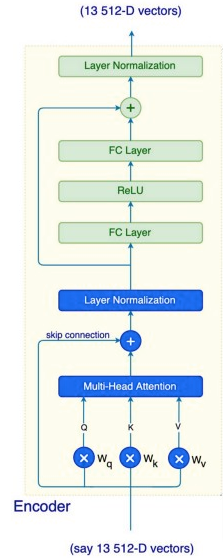
1.3 前馈网络:
如上图所示,层归一化的输出被馈送到一个全连接层、ReLU 层和另一个全连接层。这些操作分别应用于每个位置,因为每个输出都依赖于与其相关的相应注意力。
通过以上部分,您对编码器中存在的不同模块及其使用有了基本的了解。
在下一节中,让我们继续了解 BERT 的强大功能。
BERT 模型:
使用 BERT 的动机是解决这两个主要挑战:
对所有单词的深刻上下文理解。与转换器不同,它尝试实现双向词嵌入策略。
一个可以服务于多种目的的单一模型,因为从头开始为每个单独的任务进行训练,在计算上既昂贵又耗时。
理解输入:
输入包括分成标记的句子——T1、T2、… Tn。一开始,总是有一个 [CLS] 令牌。如果输入中有多个序列,则它们被 [SEP] 标记分割。输出令牌的数量与输入令牌的数量相同。请看下图以更好地理解。
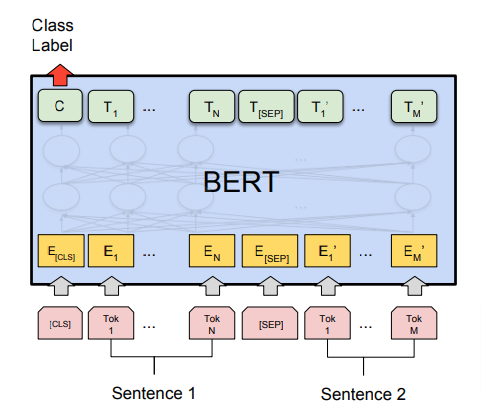
输入嵌入包括三种——令牌嵌入、段嵌入和位置嵌入。
1、令牌嵌入——为了计算嵌入,输入令牌使用固有词汇表(大小 – 30,000 个令牌)转换为单词片段。 例如,“bullying”这个词将被拆分为“bully”和“ing”。
2、Segment Embeddings——这些嵌入确保了每个标记的序列标记,以确定标记属于哪个序列。 为了做到这一点,嵌入值添加了一个常量偏移量,其值决定了它所属的序列。
3、 位置嵌入——这有助于跟踪令牌的位置。
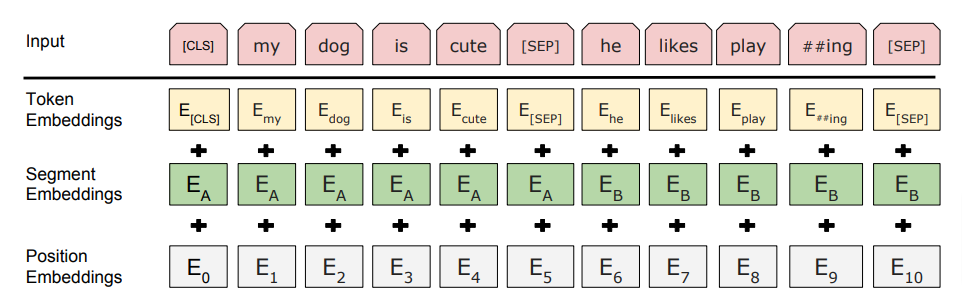
最终的嵌入将是 Token 嵌入、Segment 嵌入和位置嵌入的总和。
预训练和微调任务:
BERT 模型包括两个阶段——预训练和微调。
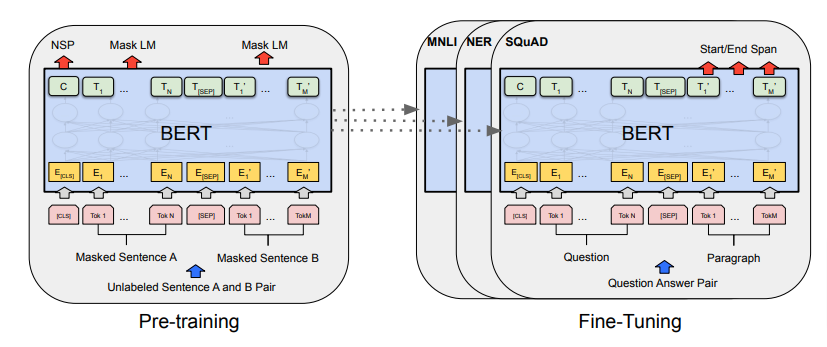
在预训练阶段,该模型使用两个 NLP 任务进行训练——(i) 掩蔽语言模型 (MLM) 和 (ii) 下一句预测 (NSP)。使用 Masked LM,解码器生成输入的向量表示,其中包含一些掩码单词。
例如,如果输入句子是——“ my cat is furry ”,那么掩码向量看起来像——“ my cat is [MASK]”。
在这种策略中,80% 的时间单词会被屏蔽。 10% 的情况下,它会被一个随机词替换——“ my cat is human ”。在剩下的 10% 的时间里,这个词保持不变——“ my cat is furry ”。这种学习方法将使模型变得健壮,因为它将提高预测准确性。需要注意的一点是,模型不会被评估预测整个序列,而只会评估缺失的单词。
第二个 NLP 任务是 Next Sentence Prediction (NSP)。输入将包含两个句子——A 和 B。这个想法是预测第二个句子是否是第一个句子的后续。这样,模型将能够学习两个句子之间的关系。模型有 50% 的时间是连续的句子,其余 50% 的序列是随机设置的。查看下图以获取 NSP 任务的示例。

总而言之,这两个训练任务能够丰富学习序列的上下文信息和语义。
BERT 模型可以针对许多不同的任务进行微调——自然语言推理 (NLI)、问答、情感分析、文本分类等。在微调的同时,我们保持完整的架构相同,除了最后一层将在自定义数据上训练模型。添加一个浅层分类器或解码器可以完成这项工作。
预训练模型:
BERT 论文提出了以下预训练模型:-
BERT-Base, Uncased:12 层,768 隐藏,12 注意力头,110M 参数
BERT-Large, Uncased:24 层,1024 隐藏,16 注意力头,340M 参数
BERT-Base,Cased:12 层,768 隐藏,12 注意力头,110M 参数
BERT-Large,Cased:24 层,1024 隐藏,16 注意力头,340M 参数
代码实现:
现在,让我们使用 BERT 实现一个多标签文本分类模型。
多标签文本分类概述
那么,什么是多标签文本分类?它基本上是将文本分类为它所属的一个或多个类别。例如,考虑电影《神奇女侠》的影评——“在一个痴迷于有缺陷的英雄、不受欢迎的英雄和反英雄的娱乐环境中,戴安娜毫无歉意地是一个真正的英雄”。从这段文字可以预测,这部电影属于“奇幻”、“冒险”和“科幻”的类型。
因此,为了解决多标签分类任务,第一步是创建由清洁文本和单热编码目标向量组成的数据。例如,在上述情况下,目标向量可能看起来像 – [0,0,1,0,1,0,1,0,0…] 其中 1 代表类别 – 幻想、冒险和科幻,而 0代表剩余的缺席类别。第二步是创建词嵌入,最后在这些嵌入上训练模型。
使用 BERT 进行多标签文本分类:
第 1 步:安装:
使用以下命令在 google colab 上安装 simpletransformers 库:
!pip install simpletransformers
Simpletransformers 是一个建立在著名的变形金刚库 – Hugging Face 之上的库。这使得只使用几行代码就可以进行预处理、训练和评估。
第 2 步:加载和预处理数据:
我们将致力于有毒评论分类的 kaggle 挑战,其中文本需要分为六个类别——有毒、严重有毒、淫秽、威胁、侮辱和身份仇恨。数据集可以从这里下载。将下载的文件存储在您当前的工作目录中。我们将使用 train.csv 文件来创建训练和评估数据。
# Import statements
import pandas as pd
from sklearn.model_selection import train_test_split
from simpletransformers.classification import MultiLabelClassificationModel
# ’dir’ would be your current working directory
df = pd.read_csv('dir/train.csv')
# taking nearly 15,000 samples out of nearly 1,50,000 samples
df= df.sample(frac=0.1)
# Combining all the tags into a single list
df['labels'] = df[df.columns[2:]].values.tolist()
# Removing '\n' from the text
df['text'] = df['comment_text'].apply(lambda x: x.replace('\n', ' '))
# Creating new dataframe consisting of just text and their labels
new_df = df[['text', 'labels']].copy()
# Splitting the data into training and testing sets, 80% of data is kept for training and 20% for evaluation
train, eval = train_test_split(new_df, test_size=0.2)第 3 步:加载预训练的 BERT 模型:
在这里,我们将使用 roberta 模型的预训练“roberta-base”版本。 RoBERTa 代表 Robustly Optimized BERT Pretraining Approach。 由于原始 BERT 模型的以下变化,RoBERTa 提高了性能——更长的训练、使用更多数据以及更长的训练序列、动态掩码模式以及从预训练任务中删除下一句预测目标。
'''
Description of params:
model_type: type of the model from the following {'bert', 'xlnet', 'xlm', 'roberta', 'distilbert'}
model_name: choose from a list of current pretrained models {roberta-base, roberta-large} roberta-base consists of 12-layer, 768-hidden, 12-heads, 125M parameters.
num_labels: number of labels(categories) in target values
args: hyperparameters for training. max_seq_length truncates the input text to 512. 512 because that is the standard size accepted as input by the model.
'''
model = MultiLabelClassificationModel('roberta', 'roberta-base', num_labels=6, args={'train_batch_size':2, 'gradient_accumulation_steps':16, 'learning_rate': 3e-5, 'num_train_epochs': 2, 'max_seq_length': 512})步骤4:训练模型
# train_model is an inbuilt function which directly trains the data with the specified parameter args. Output_dir is the location for the model weights to be stored in your directory.
model.train_model(train, multi_label=True, output_dir='/dir/Output')
步骤5:评估模型
'''
Description of params:
result: Label Ranking Average Precision (LRAP) is reported in the form of a dictionary
model_outputs: Returns model predictions in the form of probabilities for each sample in the evaluation set
wrong_predictions: Returns a list for each incorrect prediction
'''
# eval_model is an inbuilt method which performs evaluation on the eval dataframe
result, model_outputs, wrong_predictions = model.eval_model(eval)
# Converting probabilistic scores to binary - 0/1 values using 0.5 as threshold
for i in range(len(model_outputs)):
for j in range(6):
if model_outputs[i][j]<0.5:
model_outputs[i][j] = 0
else:
model_outputs[i][j] = 1第 6 步:预测:
test.csv 文件也将从此处下载到数据集中。 它只包含文本,不包含标签。
# Reading the test data for prediction
test_data = pd.read_csv('dir/test.csv')
# Replacing '\n' values in the text
predict_data = test_data.comment_text.apply(lambda x: x.replace('\n', ' '))
# Convert the dataframe to a list as the predict function accepts a list
predict_data = predict_data.tolist()
# Makes predictions for the test data
predictions, outputs = model.predict(predict_data) 结论:
在本文中,我们深入探讨了 BERT 模型。 我们还对变压器使用的编码器模块有了基本的了解。 BERT 模型由于其双向编码的特性而被证明比其他以前的模型具有优势。 该模型经过预训练,可以针对自然语言推理 (NLI)、情感分析、多类/多标签文本分类等多项任务进行微调。 该模型通过大幅减少针对不同目的的不同模型从头开始训练的需求,无疑提高了多个领域的准确性。
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
