2625 / 5000
在对Spark Streaming和Kafka Streaming进行比较并得出何时使用哪个比较之前,让我们首先对Data Streaming的基础知识有一个清晰的了解:它是如何出现的,流是什么,如何运行,其协议和用例。 。 数据流如何诞生? 从那时起,数据一直是操作的重要组成部分。数据构成了整个操作结构的基础,其中数据被进一步处理以在系统的不同实体模块中使用。这就是为什么它已成为IT领域的典型代表。 随着技术的发展,数据的重要性变得更加突出。数据处理中使用的方法已经发生了显着变化,以适应软件机构对数据输入的不断增长的需求。 随着时间的增长,数据处理的时间框架急剧缩短,以至于立即处理的输出有望满足最终用户的更高期望。随着人工智能的出现,人们强烈希望为看起来像人类的最终用户提供实时帮助。 此要求仅取决于数据处理强度。越快越好。因此,结果是处理数据的方式发生了变化。较早之前,在指定的延迟之后,有成批的输入被输入到系统中,从而将处理后的数据作为输出。 目前,这种延迟(延迟)是输入性能,处理时间和输出的结果,这已成为性能的主要标准之一。为了确保高性能,延迟必须最小化到几乎是实时的程度。 这就是数据流出现的方式。在数据流处理中,实时数据流作为输入传递,必须立即进行处理,并实时传递输出信息流。
什么是数据流?
数据流传输是一种方法,其中不按常规的批处理方式发送输入,而是以连续流的形式发布该流,并按原样使用算法进行处理。还以连续数据流的形式检索输出。 该数据流是使用数千个源生成的,这些源同时以小尺寸发送数据。这些文件背对背发送时形成连续的流程。这些可能是大量发送的日志文件以进行处理。 这种作为流出现的数据必须被顺序处理以满足(几乎)连续实时数据处理的要求。
为什么需要数据流?
随着企业在线人数的增加以及随之而来的对数据的依赖,人们已经意识到了数据的方式。数据科学和分析技术的出现导致大量数据的处理,为实时数据分析,复杂数据分析,实时流分析和事件处理提供了可能性。
当输入数据大小庞大时,需要进行数据流传输。我们需要先存储数据,然后再将其移动以进行批处理。由于数据以多批次的形式存储,因此涉及大量时间和基础架构。为了避免所有这些情况,信息以小数据包的形式连续流传输以进行处理。数据流提供超可伸缩性,这仍然是批处理的挑战。
使用数据流传输的另一个原因是要提供近乎实时的体验,其中最终用户在输入数据时会在几秒钟或几毫秒内获得输出流。
当数据源似乎无穷无尽且无法为批处理中断时,也需要进行数据流传输。 IoT传感器在此类别中发挥了重要作用,因为它们会生成连续的读数,需要对其进行处理以得出推论。
数据流如何发生?
为了通过实时处理数据做出即时决策,可以进行数据流传输。 根据系统的规模,复杂性,容错性和可靠性要求,您可以使用工具,也可以自己构建。
自行构建它意味着您需要在编码角色之前将事件放置在诸如Kafka之类的消息代理主题中。 这里的参与者是一段代码,旨在接收来自代理中的问题的事件(即数据流),然后将输出发布回代理。
Spark是第一代Streaming Engine,它要求用户编写代码并将其放置在actor中,他们可以进一步将这些actor连接在一起。 为了避免这种情况,人们经常使用Streaming SQL进行查询,因为它使用户可以轻松地查询数据而无需编写代码。 流SQL是对SQL的扩展支持,可以运行流数据。 此外,由于SQL在数据库专业人员中已得到很好的实践,因此执行流式SQL查询将更加容易,因为它基于SQL。
这是用例的流式SQL代码,在这种情况下,如果池中的温度在2分钟内下降了7度,则必须向用户发送警报邮件。
@App:name("Low Pool Temperature Alert")
@App: description('An application which detects an abnormal decrease in swimming pools temperature.')
@source(type='kafka',@map(type='json'),bootstrap.servers='localhost:9092',topic.list='inputStream',group.id='option_value',threading.option='single.thread')
define stream PoolTemperatureStream(pool string, temperature double);
@sink(type='email', @map(type='text'), ssl.enable='true',auth='true',content.type='text/html', username='sender.account', address='sender.account@gmail.com',password='account.password', subject="Low Pool Temperature Alert", to="receiver.account@gmail.com")
define stream EmailAlertStream(roomNo string, initialTemperature double, finalTemperature double);
--Capture a pattern where the temperature of a pool decreases by 7 degrees within 2 minutes
@info(name='query1')
from every( e1 = PoolTemperatureStream ) -> e2 = PoolTemperatureStream [e1.pool == pool and (e1.temperature + 7.0) >= temperature]
within 2 min
select e1.pool, e1.temperature as initialTemperature, e2.temperature as finalTemperature
insert into EmailAlertStream;
Spark SQL提供DSL(特定于域的语言),这将有助于以不同的编程语言(例如Scala,Java,R和Python)操纵DataFrame。 它使您可以使用SQL或DataFrame API对Spark程序内部的结构化数据执行查询。 Kafka等新一代流引擎也支持Kafka SQL或KSQL形式的Streaming SQL。
尽管流处理的过程大致相同,但此处重要的是根据用例要求和可用的基础结构选择流引擎。 在得出结论之前,什么时候使用Spark Streaming和什么时候使用Kafka Streaming,让我们首先探索Spark Streaming和Kafka Streaming的基础知识,以更好地理解。
什么是Spark Streaming?
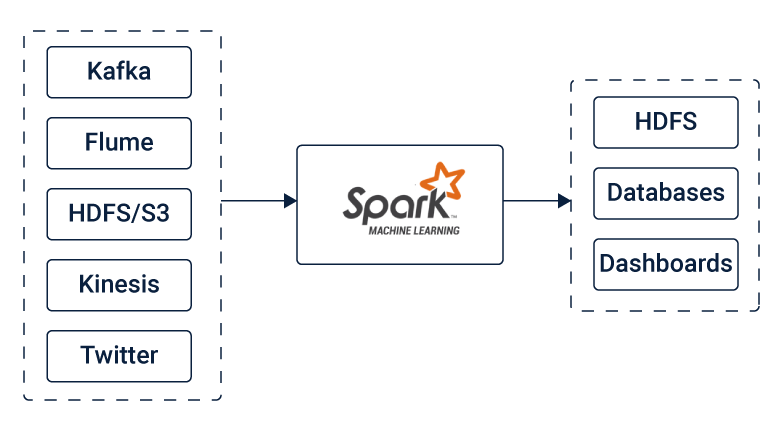
Spark Streaming是核心Spark API的扩展,可让其用户执行实时数据流的流处理。 它从Kafka,Flume,Kinesis或TCP套接字等来源获取数据。 可以使用复杂的算法对这些数据进行进一步处理,这些复杂的算法使用诸如map,reduce,join和window之类的高级功能表示。 最终输出(即处理后的数据)可以推送到诸如HDFS文件系统,数据库和实时仪表板之类的目标。
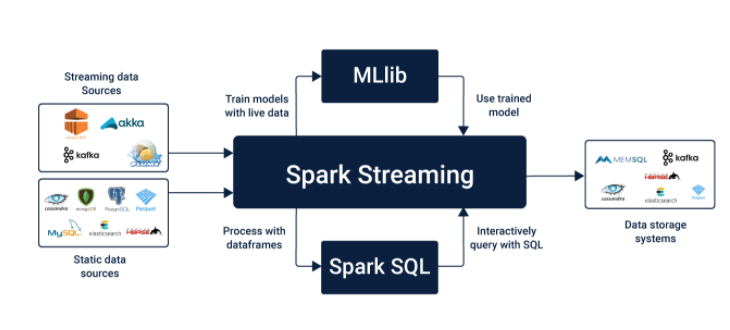
让我们仔细看看Spark Streaming的工作原理。 Spark Streaming从数据源以数据流的形式获取实时输入,并将其进一步分为几批,然后由Spark引擎处理以生成大量输出。 Spark Streaming允许您将机器学习和图形处理用于数据流以进行高级数据处理。它还提供了代表连续数据流的高级抽象。 数据流的这种抽象称为离散流或DStream。该DStream可以通过对Kafka,Flume和Kinesis等来源的数据流或其他DStream进行高级操作来创建。 这些DStream是RDD(弹性分布式数据集)的序列,RDD是分布在计算机集群上的多个只读数据集。这些RDD以容错方式进行维护,使其具有高度鲁棒性和可靠性。DStreams序列Spark Streaming使用Spark Core的快速数据调度功能来执行流分析。从诸如Kafka,Flume,Kinesis等之类的源中以迷你批的形式摄取的数据用于执行数据流处理所需的RDD转换。
Spark Streaming使您可以根据需要使用Scala,Java或Python编写程序来处理数据流(DStreams)。由于此处将用于批处理的代码用于流处理,因此使用Spark Streaming实现Lambda体系结构(将批处理和流处理混合在一起)变得容易得多。但这是以等于最小批处理持续时间的延迟为代价的。 Spark Streaming中的输入源 Spark支持主要来源,例如文件系统和套接字连接。另一方面,它也支持高级资源,例如Kafka,Flume,Kinesis。只有添加额外的实用程序类,才能获得这些出色的资源。 您可以使用以下工件链接Kafka,Flume和Kinesis。
kafka:spark-streaming-kafka-0-10_2.12
flume:spark-streaming-flume_2.12
Kinesis:spark-streaming-kinesis-asl_2.12
什么是Kafka流媒体?
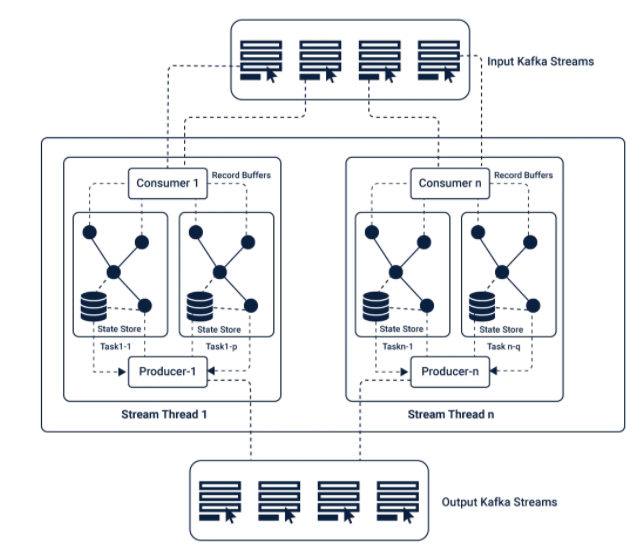
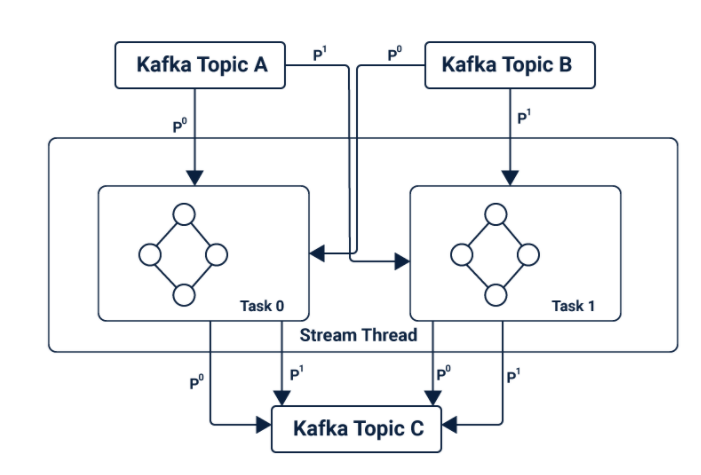
Kafka Stream是一个客户端库,可让您处理和分析从Kafka接收的数据输入,并将输出发送到Kafka或其他指定的外部系统。 Kafka依赖于流处理概念,例如: 准确区分事件时间和处理时间 窗口支持 高效直接的应用程序状态管理 通过利用Kafka中的生产者和消费者库来利用Kafka的本机功能,从而简化了应用程序开发,从而使其更加直接和快捷。正是由于这种原生的Kafka潜力,使得Kafka流式传输可以提供数据并行性,分布式协调,容错性和操作简便性。 Kafka Streaming中的主要API是提供多个高级运算符的流处理DSL(特定于域的语言)。这些运算符包括:筛选器,映射,分组,窗口,聚合,联接和表的概念。 Kafka中的消息传递层对进一步存储和传输的数据进行分区。根据状态事件在Kafka流中对数据进行分区,以进行进一步处理。通过将拓扑划分为多个任务来缩放拓扑,其中为每个任务分配了输入流中的分区列表(Kafka主题),从而提供了并行性和容错能力。
Kafka可以进行状态转换,与Spark Streaming中的批处理不同。 它在其主题内存储状态,流处理应用程序将其用于存储和查询数据。 因此,其所有操作均受状态控制。 这些状态还用于连接主题以形成事件任务.Kafka中基于状态的操作 这是由于Kafka中基于状态的操作使其具有容错能力,并允许从本地状态存储中自动恢复。 Kafka Streaming中的数据流是使用表和KStreams的概念构建的,这有助于它们提供事件时间处理。
Spark Streaming与Kafka Streaming:
何时使用什么 Spark Streaming使您可以灵活地选择任何类型的系统,包括具有lambda架构的系统。但是,Spark Streaming的延迟范围从毫秒到几秒。 如果延迟不是一个重要的问题,并且您正在寻找在源兼容性方面的灵活性,那么Spark Streaming是最佳选择。可以在EC2,Hadoop YARN,Mesos或Kubernetes上使用独立的集群模式运行Spark Streaming。 它可以访问HDFS,Alluxio,Apache Cassandra,Apache HBase,Apache Hive和许多其他数据源中的数据。它提供了容错能力,还提供了Hadoop分发。 此外,在Spark流式传输的情况下,您不必为批处理和流式传输应用程序分别编写多个代码,在这种情况下,单个系统可以同时满足这两种情况。 另一方面,如果延迟是一个重要问题,并且必须坚持以短于毫秒的时间范围进行实时处理,则必须考虑使用Kafka Streaming。由于事件驱动处理,Kafka Streaming提供了高级的容错能力,但是与其他类型的系统的兼容性仍然是一个重要的问题。此外,在高可伸缩性要求的情况下,Kafka具有最佳的可伸缩性,因此非常适合。
如果您要处理从Kafka到Kafka的本机应用程序(输入和输出数据源都在Kafka中),则Kafka流式传输是您的理想选择。 虽然Kafka Streaming仅在Scala和Java中可用,但Spark Streaming代码可以用Scala,Python和Java编写。 结束语 随着技术的发展,数据也随着时间大量增长。处理此类海量数据的需求以及对实时数据处理的日益增长的需求导致了数据流的使用。通过几种数据流方法,尤其是Spark Streaming和Kafka Streaming,全面了解用例以做出最适合需求的最佳选择变得至关重要。 在用例中优先考虑需求对于选择最合适的流技术至关重要。鉴于事实,Spark Streaming和Kafka Streaming都是高度可靠的,并且广泛推荐作为Streaming方法,它在很大程度上取决于用例和应用程序,以确保最佳效果。 在本文中,我们指出了两种流传输方法的专业领域,以便为您提供更好的分类,这可以帮助您确定优先级并做出更好的决策。