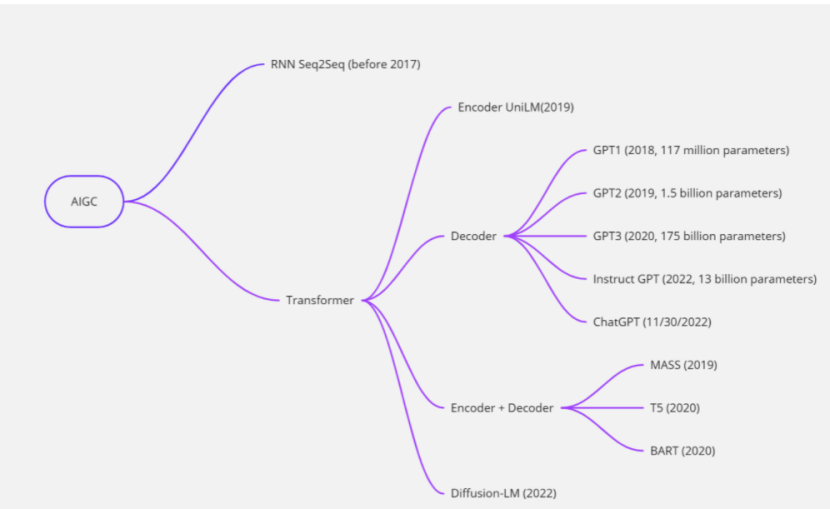
AIGC,即AI-generated Content,是一种利用人工智能进行内容创作的方式,被认为是继PGC(Professionally-generated Content)和UGC(User-generated Content)之后的一种新型内容创作方式。 AIGC在文字、图片、音视频、软件开发等多个领域发展迅速,近几年也有很多专注于AIGC的创作体验平台,用户输入一句话,让AI合成一张与之相关的图片 描述,或者更常见的是,输入一篇文章的描述,或者只是一个故事的开头,然后让 AI 为您完成文章。 它在任何需要写作或内容创建的地方都有广泛的应用,例如编写财务报告、开发代码或创建销售/营销材料。 它可以帮助人们更快地理解和分析复杂的信息,从而帮助他们做出更好的决策并产生巨大的价值。 由于技术的进步,这些提高生产力的愿景正在成为现实。
RNN Seq2Seq
长期以来,AIGC 一直以基于 RNN 的 Seq2Seq 模型为主,该模型由两个 RNN 网络组成,第一个 RNN 是编码器,第二个 RNN 是解码器。 RNN Seq2Seq 生成的文本质量通常较差,常伴有语法错误或语义不明,主要是错误传递和放大造成的。
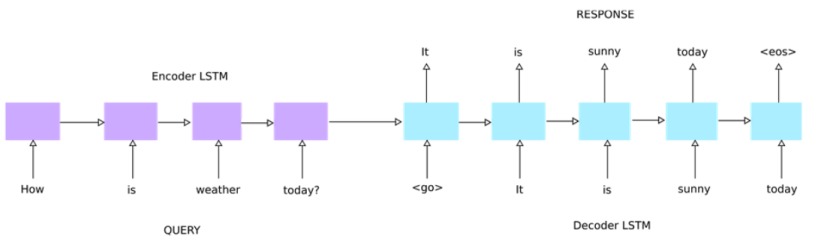
RNN Seq2Seq
2017 年,Transformer 模型结构被引入,并因其能够捕获复杂的特征表示以及与 RNN 模型相比提高了训练效率而迅速受到欢迎。 由此开发出一系列预训练模型,成为AIGC的领先技术。 下一节将概述这些模型。 Transformer 模型特别有用,因为它可以并行处理序列,导致文本编写算法研究的重点转向 Transformer 模型。
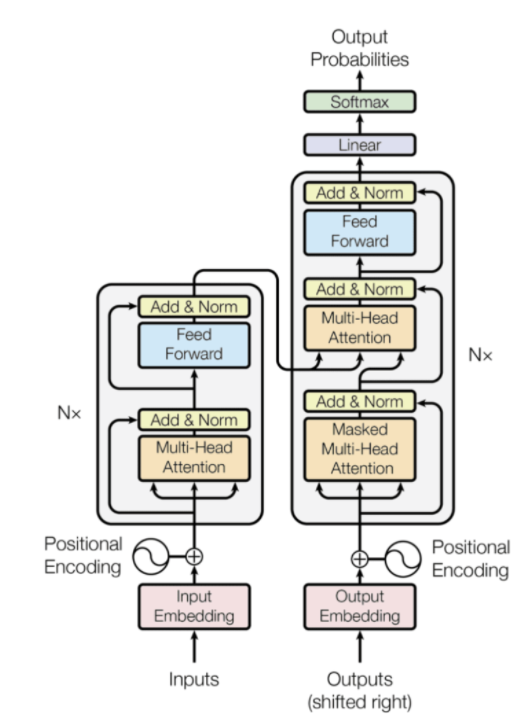
Transformer 模型体系
UniLM
UniLM,Unified Language Model的简称,是微软研究院于2019年开发的生成式BERT模型。与传统的Seq2Seq模型不同,它只利用了BERT,没有Decoder组件。 它结合了其他几种模型的训练方法,例如 L2R-LM (ELMo, GPT)、R2L-LM (ELMo)、BI-LM (BERT) 和 Seq2Seq-LM,因此称为“Unified”模型。
UniLM 模型架构(来源)
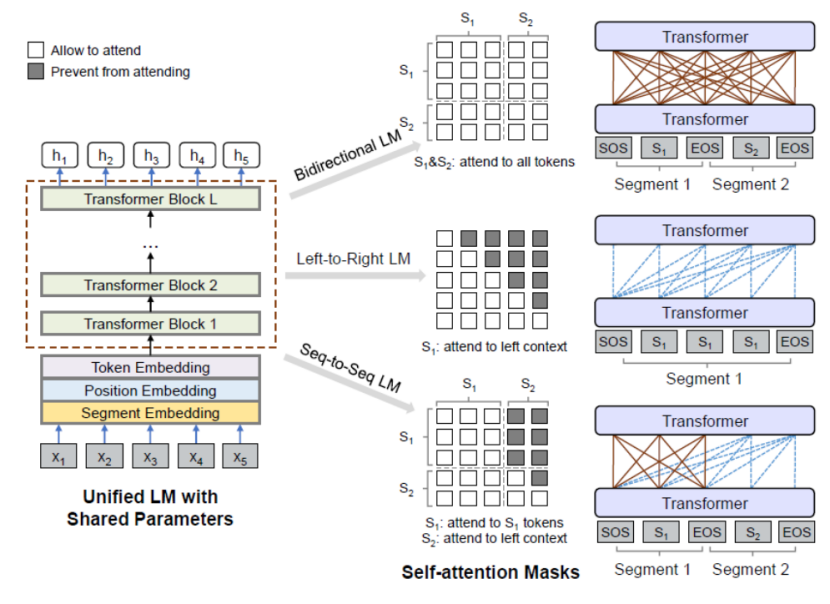
UniLM的预训练分为三个部分:Left-to-Right、Bidirectional和Seq-to-Seq。
这三种方式的区别仅在于Transformer的mask矩阵的变化:
对于Seq-to-Seq,前一句的Attention被masked用于后一句,使得前一句只能关注自己而不能关注后一句; following sentence中的每个单词对其后续单词的Attention被masked,只能关注其之前的单词;
对于Left-to-Right,Transformer的Attention只关注词本身和它前面的词,不关注它后面的词,所以mask矩阵是一个下三角矩阵;
对于 Bidirectional,Transformer 的 Attention 关注所有的词,包括 NSP 任务,就像原始的 BERT 一样。
在 UniLM 预训练过程中,这三种方法中的每一种都训练了 1/3 的时间。 与原始BERT相比,增加的单向LM预训练增强了文本表示能力,增加的Seq-to-Seq LM预训练也使得UniLM在文本生成/编写任务中表现良好。
UniLM的预训练分为三个部分:Left-to-Right、Bidirectional和Seq-to-Seq。
这三种方式的区别仅在于Transformer的mask矩阵的变化:
对于Seq-to-Seq,前一句的Attention被masked用于后一句,使得前一句只能关注自己而不能关注后一句; following sentence中的每个单词对其后续单词的Attention被masked,只能关注其之前的单词;
对于Left-to-Right,Transformer的Attention只关注词本身和它前面的词,不关注它后面的词,所以mask矩阵是一个下三角矩阵;
对于 Bidirectional,Transformer 的 Attention 关注所有的词,包括 NSP 任务,就像原始的 BERT 一样。
在 UniLM 预训练过程中,这三种方法中的每一种都训练了 1/3 的时间。 与原始BERT相比,增加的单向LM预训练增强了文本表示能力,增加的Seq-to-Seq LM预训练也使得UniLM在文本生成/编写任务中表现良好。
T5
T5,全称Text-to-Text Transfer Transformer,是谷歌在2020年提出的一种模型结构,其总体思路是使用Seq2Seq文本生成来解决所有下游任务:例如问答、摘要、分类、翻译、匹配、 continuation、denotational disambiguation 等。这种方法使所有任务能够共享相同的模型、相同的损失函数和相同的超参数。
T5的模型结构是基于多层Transformer的Encoder-Decoder结构。 T5 与其他模型的主要区别在于,GPT 家族是仅包含 Decoder 结构的自回归语言模型(AutoRegressive LM),而 BERT 是仅包含 Encoder 的自编码语言模型(AutoEncoder LM)。
文本到文本框架图。 每个任务都使用文本作为模型的输入,模型经过训练可以生成一些目标文本。 这些任务包括翻译(绿色)、语言可接受性(红色)、句子相似性(黄色)和文档摘要(蓝色)(来源)。
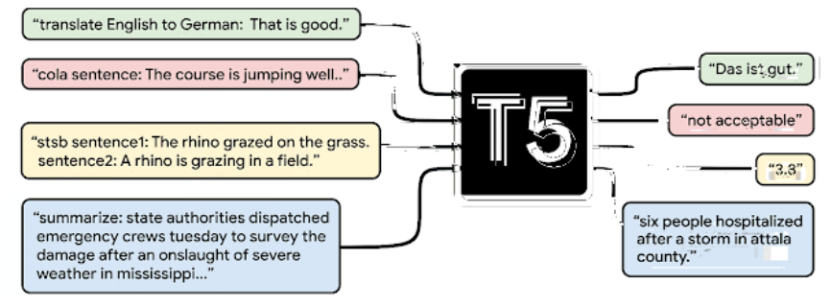
T5的预训练分为无监督和监督两部分。
无监督训练
无监督部分是类似于BERT的MLM方法,只是BERT是masking单个单词,而T5是masking一段连续的单词,即text span。 被屏蔽的文本范围仅由单个屏蔽字符替换,即屏蔽后文本的屏蔽序列长度也是未知的。 Decoder部分只输出mask的text span,其他词统一替换为集合<X>、<Y>、<Z>符号。 这样做有三个好处,一是增加了预训练的难度,显然预测未知长度的连续文本跨度是比预测单个词更难的任务,这也使得训练好的语言模型的文本表示能力更强 通用且更适应于对质量差的数据进行微调; 二是生成任务输出序列长度未知,T5的预训练很好 T5中使用的这种预训练任务也称为CTR(Corrupted Text Reconstruction)。
监督培训
监督部分使用了GLUE和SuperGLUE中包含的四大类任务:机器翻译、问答、总结和分类。 Fine-tune 的核心是将这些数据集和任务组合在一起作为一个任务,为了实现这一点,人们想到了为每个任务设计不同的前缀,与任务文本一起输入。 例如,对于翻译任务,翻译“That is good”。 从英语到德语,然后“将英语翻译成德语:很好。 目标:Das ist gut。 进入培训,“将英语翻译成德语:很好。 target:”,模型输出预测为“Das ist gut.”。 其中“将英语翻译成德语:”是为此翻译任务添加的前缀。
Supervised training
BART 代表双向和自回归变压器。 它是Facebook在2020年提出的一种模型结构,顾名思义,它是一种结合了双向编码结构和自回归解码结构的模型结构。 BART模型结构吸收了BERT中Bidirectional Encoder和GPT中Left-to-Right Decoder的特点,建立在标准的Seq2Seq Transformer模型之上,比BERT更适合文本生成场景。 同时,相对于GPT,它还拥有更多的双向上下文上下文信息。
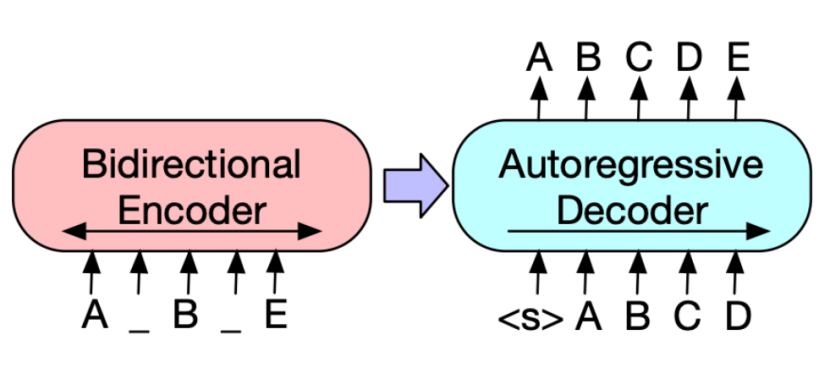
BART模型体系
BART的预训练任务采用了还原文本中[噪声]的基本思想。 BART 使用以下特定 [噪音]:
Token Masking:和BERT一样,随机选择一个token替换为[MASK];
Token Deletion:随机删除一个token,模型必须确定丢失了哪个输入;
Text Infilling:与 T5 方法类似,屏蔽一个文本范围,每个文本范围都被一个 [MASK] 标签替换。
Sentence Permutation:将输入分成多个句子,以句点为分隔符,随机打乱;
Document Rotation:随机均匀地选择一个token,并以所选token作为新的开始围绕它旋转输入,该任务训练模型识别文档的开头。
可以看出,相比于BERT或者T5,BART在Encoder端尝试各种[noise],原因和目的也很简单:
BERT 中使用的简单替换导致 Encoder 输入携带了一些关于序列结构的信息(例如序列的长度),这些信息在文本生成任务中通常不会提供给模型。
BART 使用一组更多样化的 [噪声],目的是破坏有关序列结构的信息并防止模型“依赖”它。 对于各种输入[噪声],BART在Decoder端采用统一的重构形式,即输出正确的原句。 BART 使用的预训练任务也称为 FTR(全文重建)。
通用技术
GPT代表生成预训练。 它是一种迭代预训练模型,其主要成员家族包括第一代GPT、GPT-2、GPT-3、InstructGPT,以及目前流行的ChatGPT。 下面我们一一介绍。
GPT-1
第一代GPT是OpenAI于2018年提出的预训练语言模型,其诞生早于BERT,其核心思想是基于大量未标注数据进行生成式预训练学习,然后fine- 根据特定任务调整它。 由于专注于生成式预训练,GPT模型结构只使用了Transformer的Decoder部分,其标准结构包括Masked Multi-Head Attention和Encoder-Decoder Attention。 GPT的预训练任务是SLM(Standard Language Model),根据之前的上下文(window)来预测词的当前位置,所以需要保留Mask Multi-Head Attention来屏蔽后面的context 防止信息泄露的词。 因为没有使用Encoder,所以从GPT结构中去掉了Encoder-Decoder Attention。
GPT-2
第一代GPT的问题是fine-tuning下游任务缺乏可迁移性,Fine-Tuning层不共享。 为了解决这个问题,OpenAI 在 2019 年引入了 GPT 家族的新成员:GPT-2。
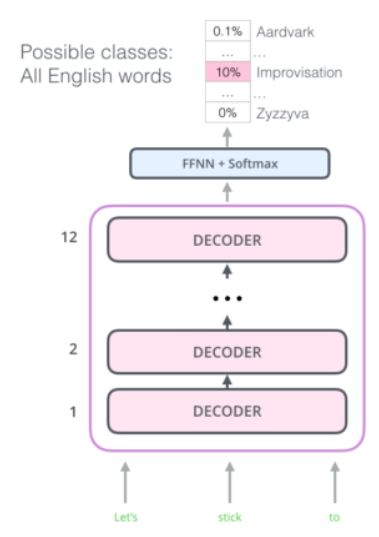
GPT-2模型体系
GPT-2 的学习目标是使用无监督的预训练模型来完成有监督的任务。 与第一代GPT相比,GPT-2有以下变化:
模型结构去掉了Fine-Tuning层,所有任务都通过为语言模型设计合理的语句进行预训练,训练需要保证每个任务的损失函数收敛;
Layer Normalization的位置移到了每个sub-block的input,在最后一个Self-Attention之后也增加了一个Layer Normalization;
使用改进的初始化方法,其中残差层的权重在初始化时缩放为1/√N倍,其中N是残差层的数量;
Vocabulary scale 扩展到 50257,输入上下文的大小从 512 扩展到 1024,并使用更大的 batch_size 进行训练。 GPT-2的多任务训练使其具有更强的泛化能力,当然这也得益于其使用了高达40G的训练语料。 GPT-2最大的贡献是验证了用海量数据和大量参数训练的模型无需额外训练即可迁移到其他类别任务的能力。
GPT-3
2020年,OpenAI在GPT-2的基础上进一步推出了GPT-3。 GPT-3的做法更简单粗暴,模型整体结构和训练目标与GPT-2相似,但GPT-3将模型规模增加到1750亿个参数(比GPT-2大115倍),使用45TB 的训练数据。 由于参数数量惊人,GPT-3 可以使用零样本和少量样本进行学习和预测,而无需进行梯度更新。
InstructGPT
超大模型GPT-3确实在生成任务方面取得了前所未有的成绩,尤其是在零样本和少样本场景下,但是GPT-3面临了一个新的挑战:模型的输出并不总是有用的,它可能会输出 不真实、有害或反映负面情绪的结果。 这种现象是可以理解的,因为预训练的任务是语言模型,预训练的目标是在输入约束下最大化输出为自然语言的可能性,而不是“用户需要安全和有用”的要求。 为了解决这个问题,OpenAI在2022年发表了基于GPT-3的重要研究:InstructGPT,引入了人类反馈强化学习(RLHF)技术。
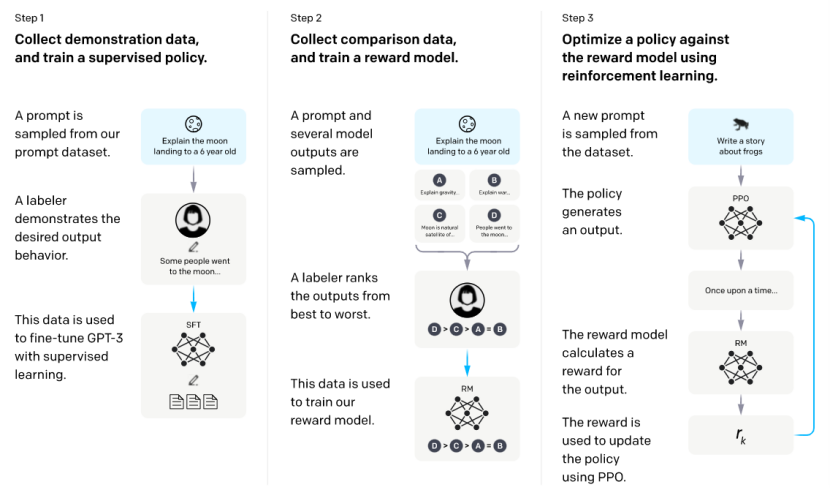
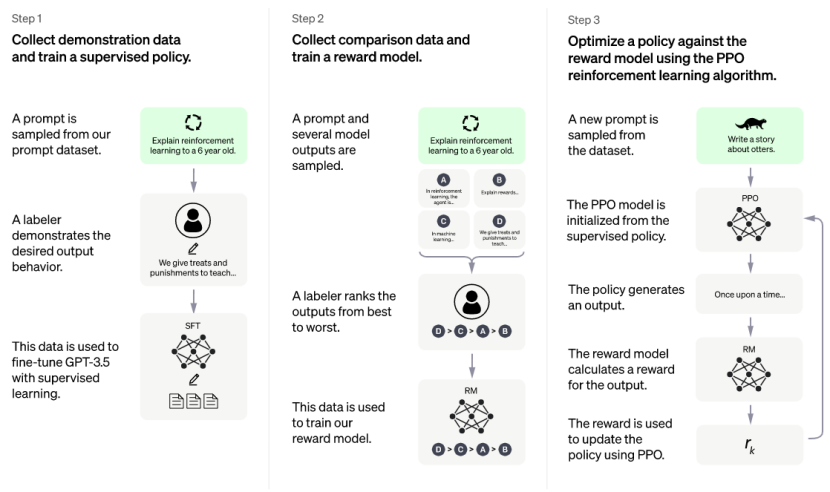
Instruct GPT处理流程
InstructGPT在模型本身方面与GPT-3没有太大变化,主要变化在训练策略上。 总体思路是让标注者为调用示例提供演示答案,然后使用这些数据对模型进行微调,使其做出更合适的响应。 其训练步骤分为三步:
收集演示数据并使用监督训练训练模型。 对提示数据集的一部分进行采样以进行手动注释,并将其用于 Fine-Tuning GPT-3。
收集对比数据并训练奖励模型。 对一批数据进行采样并将其输入到在步骤 1 中微调的模型中。注释者根据其优点对模型的输出进行排序,并使用该数据来训练奖励模型。
使用强化学习来优化模型的输出。 利用第2步得到的奖励模型,通过强化学习优化第1步微调后的模型输出,使模型输出更合适的反应。
由此产生的 InstructGPT 在 following instructions 方面比 GPT-3 好很多,而且 InstructGPT 不太可能凭空编造事实,有害输出的产生有小幅下降趋势。
ChatGPT
ChatGPT 是 OpenAI 于 2022 年 11 月 30 日正式发布的最新研究成果,它采用与 InstructGPT 相同的方法,使用从人类反馈中强化学习(RLHF)来训练模型,在数据收集方法上有所改进(未具体披露)。
ChatGPT 实战(来源)
可以看出,ChatGPT的训练过程与InstructGPT的训练过程是一致的,不同的是InstructGPT是在GPT-3上微调,而ChatGPT是在GPT-3.5上微调(GPT-3.5是OpenAI训练的模型 Q4 2021 自动化代码编写能力强)。
纵观从第一代GPT到ChatGPT的发展历程,OpenAI已经证明,使用超大数据训练超大模型,得到的预训练语言模型足以应对自然语言理解和自然语言生成等各种下游任务,甚至 无需微调,仍然可以处理零/少量样本任务。 在输出的安全性和可控性方面,OpenAI 的答案是基于人力强化学习:雇佣了 40 名全职标注员工作了近 2 年(标注时间官方未透露,作者仅从粗略推断) GPT-3和ChatGPT间隔两年半,因为强化学习需要不断迭代)为模型的输出提供标注反馈,只有有了这些数据才能进行强化学习来指导模型的优化。 Transformer+超大数据+超大模型+海量人力+强化学习,造就了今天现象级的ChatGPT。