BERT:如何处理长文档
BERT 的问题
BERT,即 Transformers 的双向编码器表示,目前是公众可以使用的最著名的预训练语言模型之一。事实证明,它在包括问答和分类在内的各种任务中非常有用。
但是,BERT 最多只能接受长度为 512 个标记的输入序列。这是一个很大的限制,因为许多常见的文档类型都比 512 个单词长得多。在这一点上,我们将解释和比较一些方法来克服这个限制,并使您更容易使用 BERT 处理更长的输入文档。
为什么 BERT 不能处理长文档?
BERT 继承了转换器的架构,转换器本身使用自注意力、前馈层、残差连接和层规范化作为其基础组件。如果您不熟悉变压器架构,您可以阅读Deep Learning 101: What is a Transformer and Why Should I Care? 在继续读本文之前。
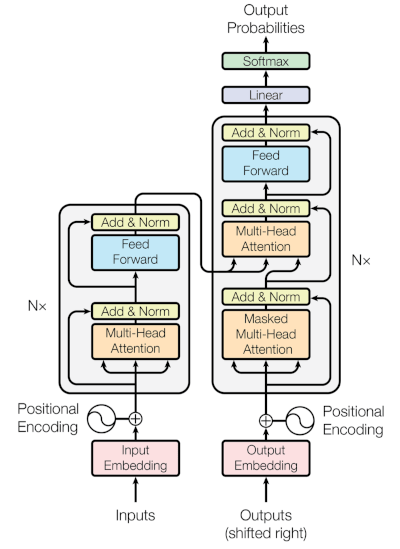
BERT 和长输入文档的问题源于 BERT 架构的几个领域。
Transformer 本身是自回归的,BERT 的创建者指出,当使用超过 512 个令牌的文档时,性能会显着下降。所以,这个限制是为了防止低质量的输出。
自注意力模型的空间复杂度为 O(n²)。像这样的二次复杂性使得这些模式非常耗费资源进行微调。输入的时间越长,微调模型所需的资源就越多。二次复杂度使大多数用户的成本高得令人望而却步。
鉴于上述两点,BERT 使用基于较短输入序列的位置编码进行了预训练。这意味着该模型不能很好地推广到更长的序列,并且为收益递减而进行微调的费用意味着解决这个问题的方法有限。
但是我的文件很长,那我现在该怎么办?
幸运的是,您可以做一些事情来有效地使用 BERT 处理更长的输入文档。这里有一些经过验证的技术可以尝试。
修整输入序列
这可能是处理 BERT 和长输入文档时最常用的技术。鉴于 BERT 对多达 512 个令牌的文档表现良好,只需将较长的文档拆分为 512 个令牌块即可让您将长文档分段传递。
对于较长的连续文档(例如长新闻文章或研究论文),将完整长度的文档切成 512 个字块不会造成任何问题,因为文档本身组织良好并且专注于单个主题。但是,如果您的文本块不太连续(例如聊天机器人脚本或一系列推文),则中间可能有与核心主题无关的块。
平均段输出的投票
另一种常见的技术是将长文档分成相等长度的重叠段,并使用投票机制进行分类。这将缓解诸如对话记录之类的非连续文档所带来的问题。使用来自较大文档的各个块的投票将合并来自整个事物的信息。
这在实践中的工作方式是将文档分成段,并通过 BERT 运行每个段,以获得分类 logits。然后通过组合投票(每段一个),我们可以得到一个平均值,我们将其作为最终分类。
这里的缺点是你不能在任务上微调 BERT,因为损失是不可微的。即使存在重叠,您也会错过每个段之间的一些共享信息。这可能会产生特定于分析管道架构的下游影响。
结论
对长输入文档使用 BERT 取决于您的具体任务。有一些更新的模型——比如 RoBERTa——是为了解决 BERT 的弱点而创建的。我们将在以后的帖子中更多地讨论这些内容。对于需要来自整个文档的信息的复杂任务,或者您使用的是非连续文档,使用像 RoBERTa 这样的 BERT 变体可能是最佳解决方案。
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
