Harmony和Android都提供了后台服务,当用户切换别的应用时,都可以使用服务来播放音乐保证不中断。
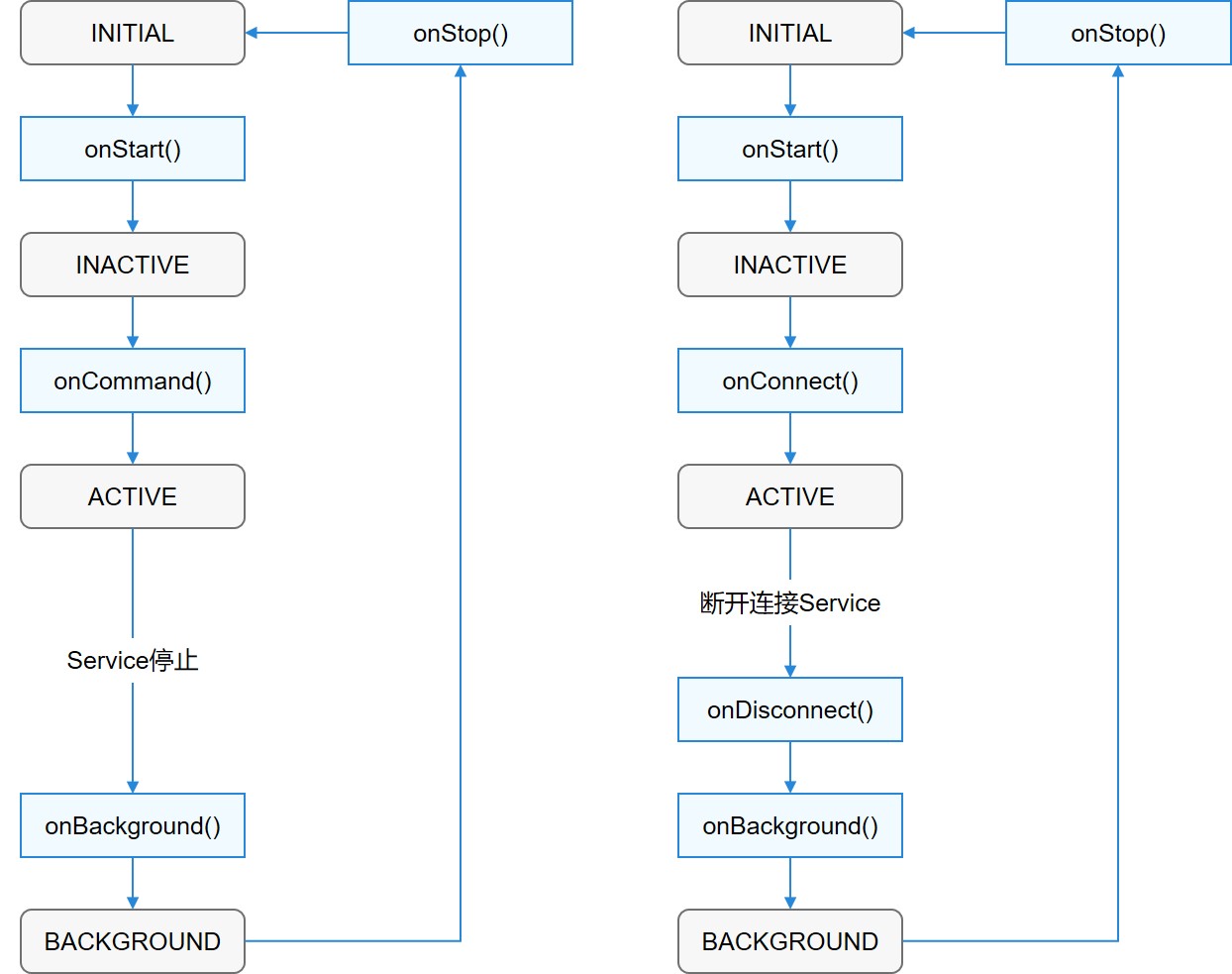 图1 鸿蒙Harmony Service Ability 生命周期
图1 鸿蒙Harmony Service Ability 生命周期
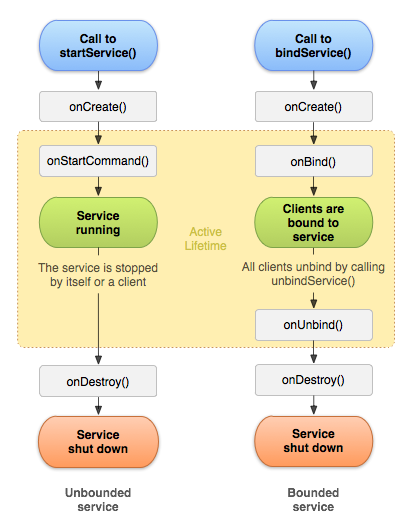 图2 Android Service的生命周期
图2 Android Service的生命周期
Harmony Service Ability:
基于Service模板的Ability(以下简称“Service”)主要用于后台运行任务(如执行音乐播放、文件下载等),但不提供用户交互界面。Service可由其他应用或Ability启动,即使用户切换到其他应用,Service仍将在后台继续运行。
Service是单实例的。在一个设备上,相同的Service只会存在一个实例。如果多个Ability共用这个实例,只有当与Service绑定的所有Ability都退出后,Service才能够退出。由于Service是在主线程里执行的,因此,如果在Service里面的操作时间过长,开发者必须在Service里创建新的线程来处理(详见线程间通信),防止造成主线程阻塞,应用程序无响应。
与Page类似,Service也拥有生命周期,如图1所示。根据调用方法的不同,其生命周期有以下两种路径:
- 启动Service该Service在其他Ability调用startAbility()时创建,然后保持运行。其他Ability通过调用stopAbility()来停止Service,Service停止后,系统会将其销毁。
- 连接Service该Service在其他Ability调用connectAbility()时创建,客户端可通过调用disconnectAbility()断开连接。多个客户端可以绑定到相同Service,而且当所有绑定全部取消后,系统即会销毁该Service。图1 Service生命周期
一般情况下,Service都是在后台运行的,后台Service的优先级都是比较低的,当资源不足时,系统有可能回收正在运行的后台Service。
在一些场景下(如播放音乐),用户希望应用能够一直保持运行,此时就需要使用前台Service。前台Service会始终保持正在运行的图标在系统状态栏显示。
使用前台Service并不复杂,开发者只需在Service创建的方法里,调用keepBackgroundRunning()将Service与通知绑定。调用keepBackgroundRunning()方法前需要在配置文件中声明ohos.permission.KEEP_BACKGROUND_RUNNING权限,同时还需要在配置文件中添加对应的backgroundModes参数。在onStop()方法中调用cancelBackgroundRunning()方法可停止前台Service。
Android Service:
Service 是一种可在后台执行长时间运行操作而不提供界面的应用组件。服务可由其他应用组件启动,而且即使用户切换到其他应用,服务仍将在后台继续运行。此外,组件可通过绑定到服务与之进行交互,甚至是执行进程间通信 (IPC)。例如,服务可在后台处理网络事务、播放音乐,执行文件 I/O 或与内容提供程序进行交互。
以下是三种不同的服务类型:前台前台服务执行一些用户能注意到的操作。例如,音频应用会使用前台服务来播放音频曲目。前台服务必须显示通知。即使用户停止与应用的交互,前台服务仍会继续运行。后台后台服务执行用户不会直接注意到的操作。例如,如果应用使用某个服务来压缩其存储空间,则此服务通常是后台服务。
注意:如果您的应用面向 API 级别 26 或更高版本,当应用本身未在前台运行时,系统会对运行后台服务施加限制。在诸如此类的大多数情况下,您的应用应改为使用计划作业。绑定当应用组件通过调用 bindService() 绑定到服务时,服务即处于绑定状态。绑定服务会提供客户端-服务器接口,以便组件与服务进行交互、发送请求、接收结果,甚至是利用进程间通信 (IPC) 跨进程执行这些操作。仅当与另一个应用组件绑定时,绑定服务才会运行。多个组件可同时绑定到该服务,但全部取消绑定后,该服务即会被销毁。
虽然本文档分开概括讨论启动服务和绑定服务,但您的服务可同时以这两种方式运行,换言之,它既可以是启动服务(以无限期运行),亦支持绑定。唯一的问题在于您是否实现一组回调方法:onStartCommand()(让组件启动服务)和 onBind()(实现服务绑定)。
无论服务是处于启动状态还是绑定状态(或同时处于这两种状态),任何应用组件均可像使用 Activity 那样,通过调用 Intent 来使用服务(即使此服务来自另一应用)。不过,您可以通过清单文件将服务声明为私有服务,并阻止其他应用访问该服务。使用清单文件声明服务部分将对此做更详尽的阐述。