在做一个需求,要求计算在不同时间段的多个最大值(波峰)和最小值(波谷),并且要求波峰和波谷是间隔出现的。
原始数据如下:
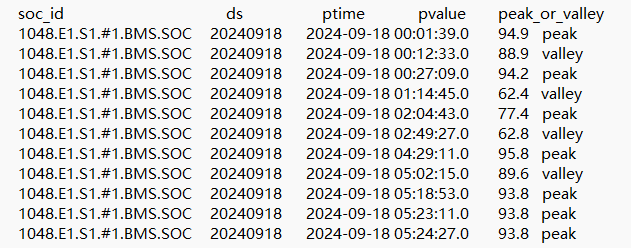
要求按时间(ptime)排序,同1个soc_id必须是1个peak和1个valley间隔,可能会有波峰波谷间隔出现多个;有多个peak连续出现时,取pvalue最大值(如果都相同取第一个值);有多个valley连续出现时,取pvalue最小值(如果都相同取第一个值)
实现代码如下:
WITH LagResult AS (
— 计算每一行的前一行的 peak_or_valley 值,用于后续分组
SELECT
soc_id,
ds,
ptime,
pvalue,
peak_or_valley,
LAG(peak_or_valley) OVER (PARTITION BY soc_id ORDER BY ptime) AS prev_peak_valley
FROM
your_table
),
GroupedPeaksAndValleys AS (
— 基于 LAG 结果生成每个 peak 和 valley 的分组编号
SELECT
soc_id,
ds,
ptime,
pvalue,
peak_or_valley,
— 通过对比当前值和前一个值是否不同来创建组号
SUM(CASE WHEN peak_or_valley != prev_peak_valley THEN 1 ELSE 0 END)
OVER (PARTITION BY soc_id ORDER BY ptime ASC) AS group_id
FROM
LagResult
),
FilteredPeaksAndValleys AS (
— 按每个分组的 peak 和 valley 排序,并选取最大或最小的 pvalue
SELECT
soc_id,
ds,
ptime,
pvalue,
peak_or_valley,
group_id,
ROW_NUMBER() OVER (PARTITION BY soc_id, group_id ORDER BY
CASE WHEN peak_or_valley = ‘peak’ THEN pvalue END DESC, — 对 peak 按 pvalue 降序
CASE WHEN peak_or_valley = ‘valley’ THEN pvalue END ASC, — 对 valley 按 pvalue 升序
ptime ASC — 在相同 pvalue 的情况下按 ptime 升序
) AS rn
FROM
GroupedPeaksAndValleys
)
SELECT
soc_id,
ds,
ptime,
pvalue,
peak_or_valley
FROM
FilteredPeaksAndValleys
WHERE
rn = 1 — 只保留每个 group 中的第一个,即 pvalue 最大/最小且时间最早的记录
ORDER BY
soc_id, ptime;
在上面的代码:
- LagResult CTE: 首先,我们通过
LAG() 函数计算出每行的前一个 peak_or_valley,这为后续分组做准备。 - GroupedPeaksAndValleys CTE: 使用
SUM(CASE ...) OVER 来生成分组编号(group_id)。当当前的 peak_or_valley 与前一个不同的时候,我们将分组编号加 1,从而将连续的相同 peak 或 valley 分为一组。 - FilteredPeaksAndValleys CTE: 对每个
group_id 中的 peak 和 valley 排序,选择 pvalue 最大(对于 peak)或最小(对于 valley)的记录,确保在 pvalue 相同时选择时间最早的记录。 - 最终结果: 按时间 (
ptime) 排序,输出满足要求的 peak 和 valley 数据。
这个查询避免了嵌套窗口函数的限制,能够正确处理连续的 peak 和 valley,并选取最大或最小的 pvalue。