对更快数据处理的需求一直在增加,实时流数据处理是目前的解决方案。虽然 Apache Spark 仍在许多组织中用于大数据处理,但 Apache Flink 已经迅速成为替代方案。事实上,许多人认为它有可能取代 Apache Spark,因为它能够实时处理流数据。当然,Flink 能否取代 Spark 尚无定论,因为 Flink 还没有经过广泛的测试。但实时处理和低数据延迟是其两个决定性特征。同时,这需要考虑到 Apache Spark 可能不会失宠,因为它的批处理能力仍然很重要。
流式数据处理案例
对于基于批处理的所有优点,实时流数据处理似乎是一个强有力的案例。流式数据处理使快速设置和加载数据仓库成为可能。具有低数据延迟的流处理器可以快速提供对数据的更多见解。所以,你有更多的时间来了解发生了什么。除了更快的处理之外,还有另一个显着的好处:您有更多的时间来设计对事件的适当响应。例如,在异常检测的情况下,更低的延迟和更快的检测使您能够确定最佳响应,这是防止安全网站受到欺诈攻击或工业设备损坏等情况的关键。因此,您可以防止重大损失。
什么是 Apache Flink?
Apache Flink 是一种大数据处理工具,以在大规模分布式系统上以低数据延迟和高容错性快速处理大数据而著称。它的定义特征是它能够实时处理流数据。
Apache Flink 最初是一个学术开源项目,当时它被称为 Stratosphere。后来,它成为了 Apache 软件基金会孵化器的一部分。为避免与其他项目名称冲突,将名称更改为 Flink。 Flink 这个名字很合适,因为它意味着敏捷。即使选择的标志,松鼠也是合适的,因为松鼠代表了敏捷、敏捷和速度的美德。
自从加入 Apache 软件基金会后,它作为大数据处理工具迅速崛起,并在 8 个月内开始受到更广泛受众的关注。人们对 Flink 的兴趣日益浓厚,这反映在 2015 年的多次会议的参会人数上。2015 年 5 月在伦敦举行的 Strata 会议和 2015 年 6 月在圣何塞举行的 Hadoop 峰会上,有很多人参加了关于 Flink 的会议。 2015 年 8 月,超过 60 人参加了在圣何塞 MapR 总部举办的湾区 Apache Flink 聚会。
下图给出了 Flink 的 Lambda 架构。
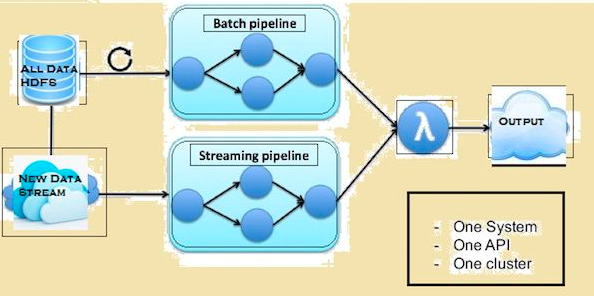
Spark 和 Flink 的比较
虽然 Spark 和 Flink 之间有一些相似之处,例如它们的 API 和组件,但在数据处理方面,相似之处并不重要。 下面给出了 Flink 和 Spark 之间的比较。
数据处理
Spark 以批处理模式处理数据,而 Flink 实时处理流数据。 Spark 处理数据块,称为 RDD,而 Flink 可以实时处理一行一行的数据。 因此,虽然 Spark 始终存在最小数据延迟,但 Flink 并非如此。
迭代
Spark 支持批量数据迭代,但 Flink 可以使用其流式架构原生迭代其数据。 下图显示了迭代处理是如何发生的。
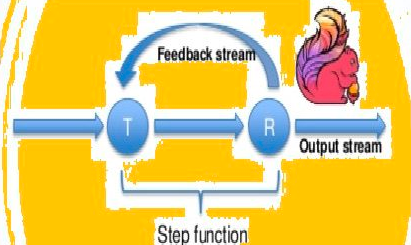
内存管理
Flink 可以自动适应不同的数据集,但 Spark 需要手动优化和调整其作业以适应单个数据集。 Spark 也进行手动分区和缓存。因此,预计处理会有所延迟。
数据流
Flink 能够在需要时为其数据处理提供中间结果。 Spark 遵循过程式编程系统,而 Flink 遵循分布式数据流方法。因此,当需要中间结果时,广播变量用于将预先计算的结果分发到所有工作节点。
数据可视化
Flink 提供了一个 Web 界面来提交和执行所有作业。 Spark 和 Flink 都与 Apache Zeppelin 集成,并提供数据摄取、数据分析、发现、协作和可视化。 Apache Zeppelin 还提供了多语言后端,允许您提交和执行 Flink 程序。
处理时间
以下段落提供了 Flink 和 Spark 在不同作业中所用时间的比较。
为了公平比较,Flink 和 Spark 都以机器规格和节点配置的形式获得了相同的资源。
Flink 处理速度更快,因为它的流水线执行。 处理数据,Spark 用了 2171 秒,而 Flink 用了 1490 秒。
当执行不同数据大小的 TeraSort 时,结果如下:
对于 10 GB 的数据,Flink 需要 157 秒,而 Spark 需要 387 秒。
对于 160 GB 的数据,Flink 需要 3127 秒,而 Spark 需要 4927 秒。
基于批处理或流式数据——哪个过程更好?
这两种工艺各有优势,适用于不同的情况。 尽管许多人声称基于批处理的工具正在失宠,但它不会很快发生。 要了解它们的相对优势,请参见以下比较:
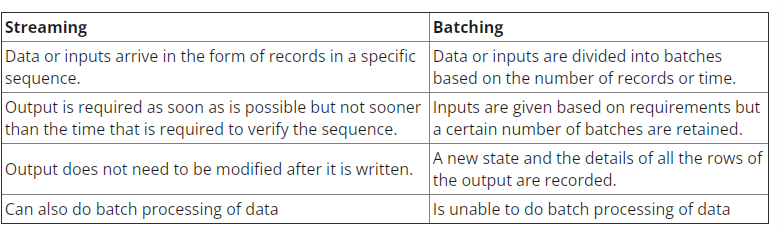
在个别情况下,Flink 和 Spark批 处理都是有用的。以每天计算滚动月销售额的用例为例。在此活动中,需要计算每日销售总额,然后进行累计。在这样的用例中,可能不需要对数据进行流式处理。数据的批处理可以根据日期处理各个批次的销售数据,然后将它们添加。在这种情况下,即使存在一些数据延迟,也可以在稍后将该潜在数据添加到以后的批次中时弥补这些延迟。
有类似的用例需要流处理。以计算每个访问者在网站上花费的每月滚动时间的用例为例。在网站的情况下,访问次数可以每小时、每分钟甚至每天更新一次。但是这种情况下的问题是定义会话。定义会话的开始和结束可能很困难。此外,难以计算或识别不活动的时间段。因此,在这种情况下,定义会话甚至不活动时间段都没有合理的界限。在这种情况下,需要实时处理流数据。
概括
虽然 Spark 在批处理数据处理方面有很多优势,而且它仍然有很多使用场景,但 Flink 似乎正在迅速获得商业方面应用的青睐。 Flink 也可以进行批处理这一事实似乎对其有利。当然,这需要考虑到 Flink 的批处理能力可能与 Spark 不在一个级别。