Elsticsearch 数据写入流程
前言
由于Elasticsearch使用Lucene来处理shard级别的索引和查询,因此数据目录中的文件由Elasticsearch和Lucene共同编写。
Lucene负责编写和维护Lucene索引文件,而Elasticsearch在Lucene之上编写与功能相关的元数据,例如字段映射,索引设置和其他集群元数据,用户和支持功能由Elasticsearch提供。
ES数据
Node Data
只需启动ES就会有生成下面的目录树:
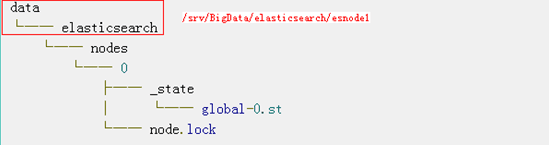
node.lock:为了确保一次只有一个ES应用从这个数据目录读取/写入。
global-0.st:global-prefix表示这是一个全局状态的文件,而.st扩展名表示这是一个包含元数据状态的文件。这个二进制文件是包含集群的全局元数据,前缀后的数字表示集群元数据版本,这是一个严格增加的版本控制方案。版本号跟随集群而变。
不要去编辑这些文件,因为有可能会导致数据丢失。
Index Data
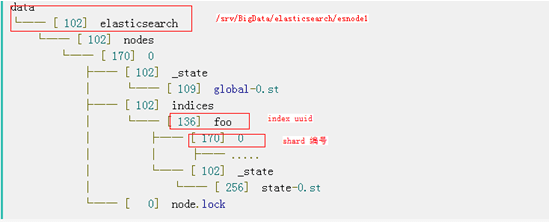
当我们创建index,文件目录发生变化:

此时可以看出,已经创建了与索引名称对应的新目录。目录有两类子文件夹:_state和0.。
_state包含state-{version}.st索引状态文件,包含了索引的元数据,例如:创建的时间戳。还包含唯一标识符以及索引的settings和mappings。
数字0表示的shard编号,这个文件夹包含了shard相关的数据。
Shard Data
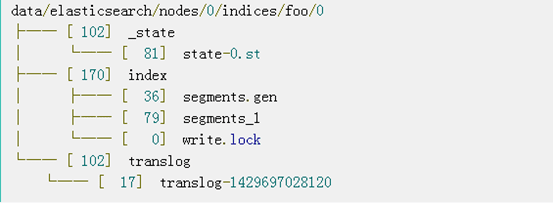
_state目录包含shard的状态文件,其中包含版本控制以及有关分片是主分片还是副本的信息。
index目录包含Lucene拥有的文件。ES通常不直接写入此文件夹。这些文件构成了ES数据目录的大小。
translog:ES事物日志。ES事物日志确保数据可以安全的写入到索引中,而无需为每个文档执行Lucene commit。提交Lucene index会产生一个新的segment,即fsync()-ed,会导致大量的磁盘I/O,从而影响性能。
Lucene数据
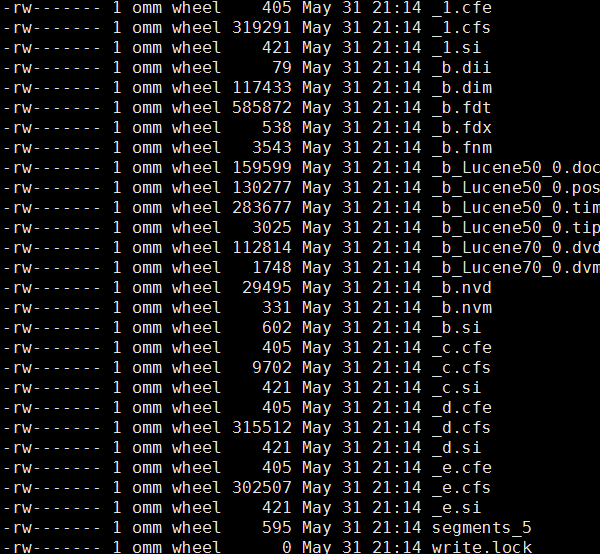
Lucene文件如下表所示:
| Name | Extension | Brief Description |
| Segemnts File | segments_N | 存储lucene数据文件的元信息,记录所有segment的元数据信息。主要记录了当前有多少个segment,每个segment有一些基本信息,更新这些信息能定位到每个segment的元信息文件。 |
| Lock File | write.lock | 防止多个IndexWriters写入同一个文件 |
| Segement Info | .si | 存储有关段的元数据 |
| Compound File | .cfs,.cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 存储fileds的相关信息 |
| Fields Index | .fdx | 正排存储文件的元数据信息 |
| Fields Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中位置 |
| Positions | .pos | 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Playloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd,.nvm | 存储索引字段加权数据 |
| Per-Document Values | .dvd,.dvm | Lucene的docvalues文件,即列式存储,用作聚合和排序 |
| Term Vector Data | .tvx,.tvd,.tvf | 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
数据写入流程
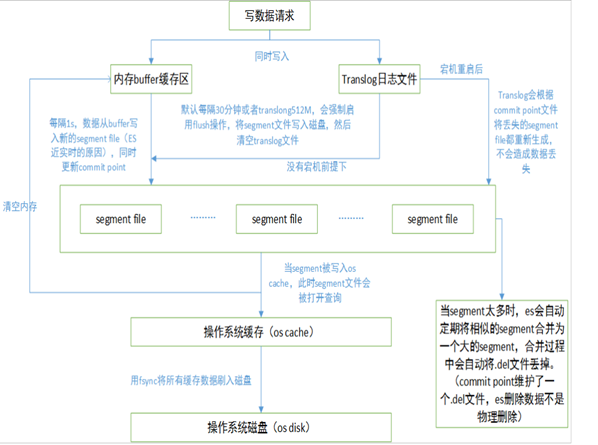
1.segment file: 存储倒排索引的文件,每个segment本质上就是一个倒排索引,每秒都会生成一个segment文件,当文件过多时es会自动进行segment merge(合并文件),合并时会同时将已经标注删除的文档物理删除;
2.commit point(重点理解): 记录当前所有可用的segment,每个commit point都会维护一个.del文件(es删除数据本质是不属于物理删除),当es做删改操作时首先会在.del文件中声明某个document已经被删除,文件内记录了在某个segment内某个文档已经被删除,当查询请求过来时在segment中被删除的文件是能够查出来的,但是当返回结果时会根据commit point维护的那个.del文件把已经删除的文档过滤掉;
3.translog日志文件: 为了防止elasticsearch宕机造成数据丢失保证可靠存储,es会将每次写入数据同时写到translog日志中。
translog的写入也可以设置,默认是request,每次请求都会写入磁盘(fsync),这样就保证所有数据不会丢,但写入性能会受影响;如果改成async,则按照配置触发trangslog写入磁盘,注意这里说的只是trangslog本身的写盘。
4. flush:translog什么时候清空?默认是512mb,或30分钟。这个动作就是flush,同时伴随着segment提交(写入磁盘)。flush之后,这段translog的使命就完成了,因为segment已经写入磁盘,就算故障,也可以从segment文件恢复。
5.fsync:另外,有一个/_flush/sync命令,在做数据节点维护时很有用。其逻辑就是flush translog并且将sync_id同步到各个分片。可以实现快速恢复。
综述:fsync指的是translog本身被写入磁盘的动作;flush指的是逻辑上的刷新,包含一系列逻辑操作。
其实flush API的作用是强制停止translog的fsync行为,提交segment并清除translog。间隔要尽量大一点(需要优化写速度的话,就稍微调大一点flush间隔。)
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
