Jaccard 相似度 – NLP 中的文本相似度度量
Jaccard 相似度也称为 Jaccard 指数和联合交集。用于确定两个文本文档之间的相似性的 Jaccard 相似度矩阵是指两个文本文档在上下文方面彼此接近的程度,即在总词中存在多少常用词。
在自然语言处理中,我们经常需要估计文本文档之间的文本相似度。存在许多文本相似度矩阵,例如余弦相似度、Jaccard 相似度和欧几里得距离测量。所有这些文本相似度指标都有不同的行为。
在本教程中,您将通过示例详细了解 Jaccard 相似度矩阵。您还可以参考本教程来探索余弦相似度指标。
Jaccard 相似度定义为两个文档的交集除以这两个文档的并集,这两个文档指的是总单词数中的常用单词数。在这里,我们将使用单词集来查找文档的交集和并集。
Jaccard 相似度的数学表示为:
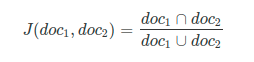
Jaccard Similarity 得分在 0 到 1 的范围内。如果两个文档相同,则 Jaccard Similarity 为 1。如果两个文档之间没有共同词,则 Jaccard 相似度得分为 0。
让我们看一下 Jaccard Similarity 如何工作的示例?
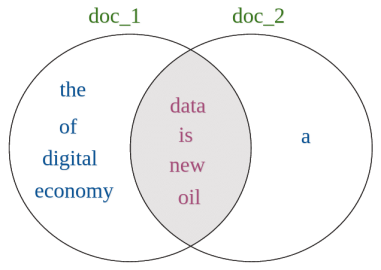
doc_1 = "Data is the new oil of the digital economy"
doc_2 = "Data is a new oil"让我们为每个文档获取一组唯一的单词。
words_doc1 = {'data', 'is', 'the', 'new', 'oil', 'of', 'digital', 'economy'}
words_doc2 = {'data', 'is', 'a', 'new', 'oil'}现在,我们将计算这两组词的交集和并集,并测量 doc_1 和 doc_2 之间的 Jaccard 相似度。

查找 Jaccard 相似性的 Python 代码
让我们为 Jaccard Similarity 编写 Python 代码。
def Jaccard_Similarity(doc1, doc2):
# List the unique words in a document
words_doc1 = set(doc1.lower().split())
words_doc2 = set(doc2.lower().split())
# Find the intersection of words list of doc1 & doc2
intersection = words_doc1.intersection(words_doc2)
# Find the union of words list of doc1 & doc2
union = words_doc1.union(words_doc2)
# Calculate Jaccard similarity score
# using length of intersection set divided by length of union set
return float(len(intersection)) / len(union)doc_1 = "Data is the new oil of the digital economy" doc_2 = "Data is a new oil" Jaccard_Similarity(doc_1,doc_2)
0.44444
doc_1 和 doc_2 之间的 Jaccard 相似度为 0.444
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
