Logstash和flume全方位对比
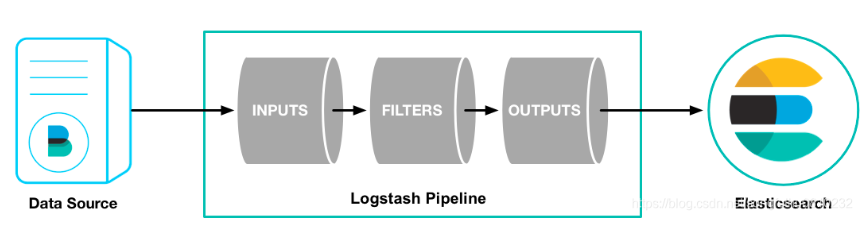
Logstash架构如下:
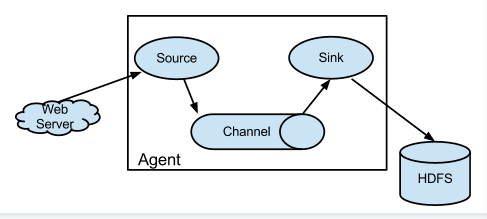
Flume架构如下:
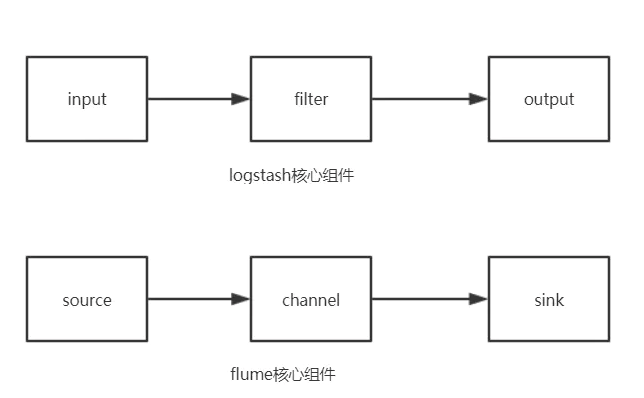
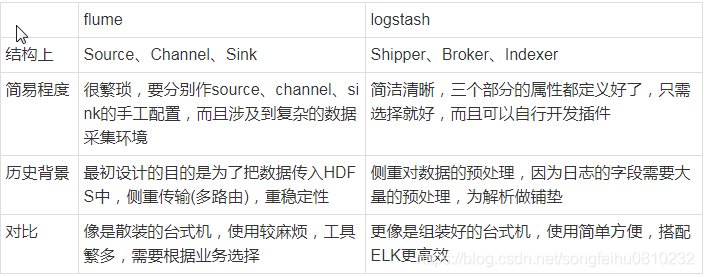

首先从结构对比,我们会惊人的发现,两者是多么的相似!Logstash的Shipper、Broker、Indexer分别和Flume的Source、Channel、Sink各自对应!只不过是Logstash集成了,Broker可以不需要,而Flume需要单独配置,且缺一不可,但这再一次说明了计算机的设计思想都是通用的!只是实现方式会不同而已。
从程序员的角度来说,上文也提到过了,Flume是真的很繁琐,你需要分别作source、channel、sink的手工配置,而且涉及到复杂的数据采集环境,你可能还要做多个配置,这在上面提过了,反过来说Logstash的配置就非常简洁清晰,三个部分的属性都定义好了,程序员自己去选择就行,就算没有,也可以自行开发插件,非常方便。当然了,Flume的插件也很多,但Channel就只有内存和文件这两种(其实现在不止了,但常用的也就两种)。读者可以看得出来,两者其实配置都是非常灵活的,只不过看场景取舍罢了。
其实从作者和历史背景来看,两者最初的设计目的就不太一样。Flume本身最初设计的目的是为了把数据传入HDFS中(并不是为了采集日志而设计,这和Logstash有根本的区别),所以理所应当侧重于数据的传输,程序员要非常清楚整个数据的路由,并且比Logstash还多了一个可靠性策略,上文中的channel就是用于持久化目的,数据除非确认传输到下一位置了,否则不会删除,这一步是通过事务来控制的,这样的设计使得可靠性非常好。相反,Logstash则明显侧重对数据的预处理,因为日志的字段需要大量的预处理,为解析做铺垫。
为什么先讲Logstash然后讲Flume?这里面有几个考虑,
其一:Logstash其实更有点像通用的模型,所以对新人来说理解起来更简单,而Flume这样轻量级的线程,可能有一定的计算机编程基础理解起来更好;
其二:目前大部分的情况下,Logstash用的更加多,这个数据我自己没有统计过,但是根据经验判断,Logstash可以和ELK其他组件配合使用,开发、应用都会简单很多,技术成熟,使用场景广泛。相反Flume组件就需要和其他很多工具配合使用,场景的针对性会比较强,更不用提Flume的配置过于繁琐复杂了。
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
