Flume pollDelay设置不正确停止采集
使用FusionInsight HD Flume从本地采集静态日志( Spooling Source )保存到Kafka,由于采集堆积太多了,flume配置参数做了一些修改。后来发现一个诡异问题:每次重启flume采集,只采集1、2个文件就停止采集了,也没报什么错误。
采用对比法排查问题,对比正常运行的flume配置,看到pollDelay跟之前的不同。才想起之前一顿三百五的操作:想加快速度。pollDelay的设置值从5000改成500。
采集方案采用的Spooling Source + Memory Channel + kfaka
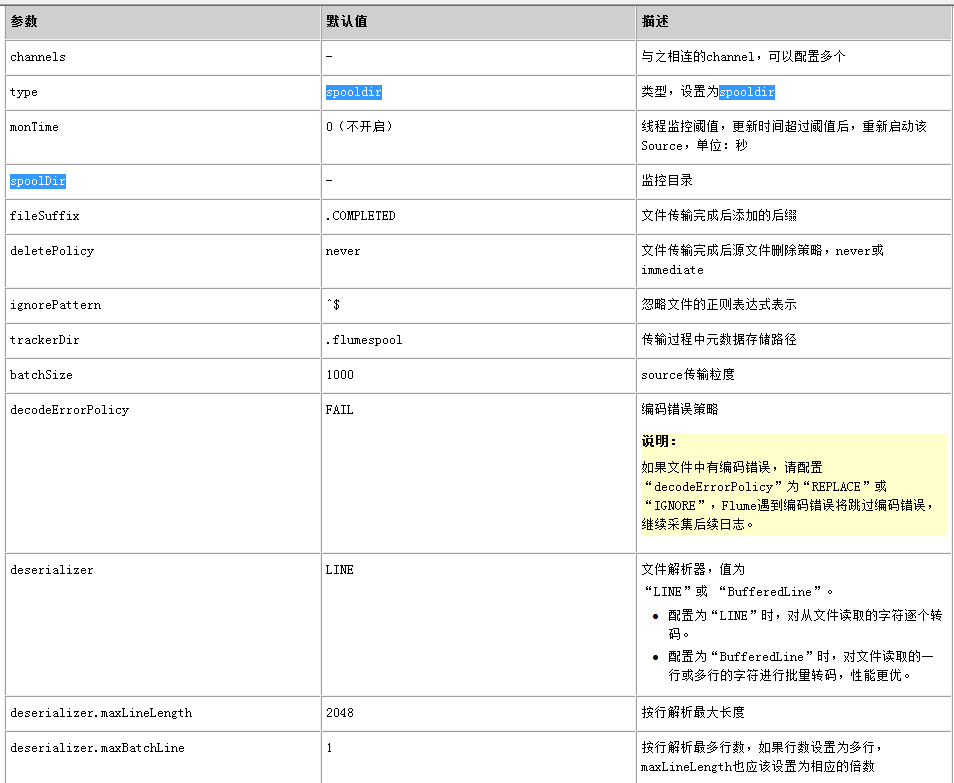
Spooling Source常用配置 :
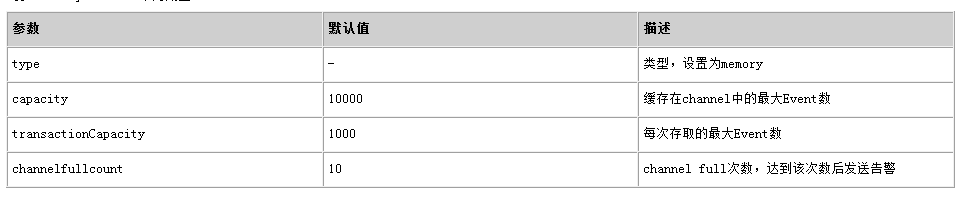
Memory Channel使用内存作为缓存区,Events存放在内存队列中。常用配置如下表所示:
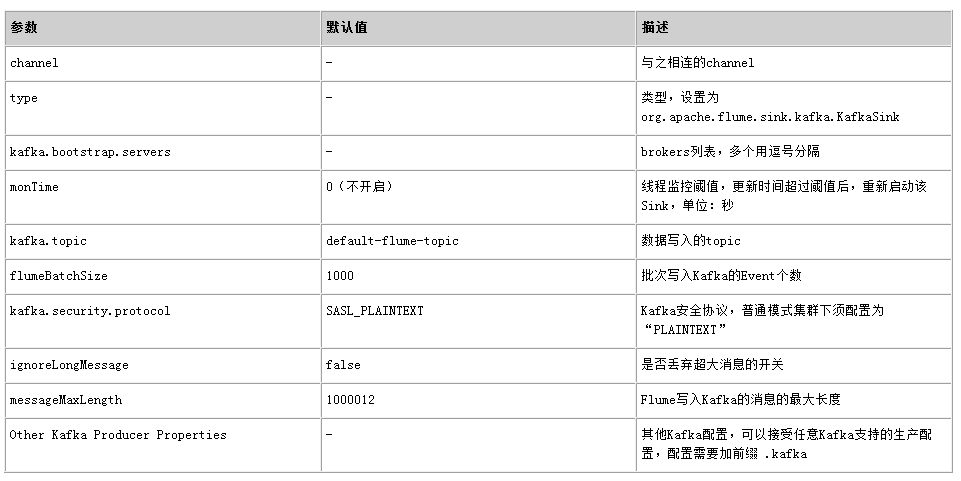
Kafka Sink将数据写入到Kafka中。常用配置如下表所示:
参考配置如下:
a1.channels = c1
a1.sources = s1
a1.sinks = sink1
a1.sources.s1.type = spooldir
a1.sources.s1.channels = c1
a1.sources.s1.spoolDir = /home/ftp (填写实际的路径)
a1.sources.s1.bufferMaxLineLength = 1073741824
a1.sources.s1.pollDelay = 5000
a1.sources.s1.consumeOrder = random
a1.channels.c1.type = memory
a1.channels.c1.capacity = 30000
a1.channels.c1.tansactionCapacity = 30000
a1.sinks.sink1.channel = c1
a1.sinks.sink1.type = org.apache.kafka.kafkaSink
a1.sinks.sink1.bootstrap.servers=192.168.1.1:210007 (根据实际填写)
a1.sinks.sink1.topic = mytopic (根据实际填写)
a1.sinks.sink1.batchSize = 200
a1.sinks.sink1.producer.requiredAcks = 1
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
