大数据即席查询框架技术选型
目前应用比较广泛的几种即席查询框架有Druid、Kylin、Presto、Impala、Spark SQL和Elasticsearch,针对响应时间、数据支持、技术特点等方面的对比如表
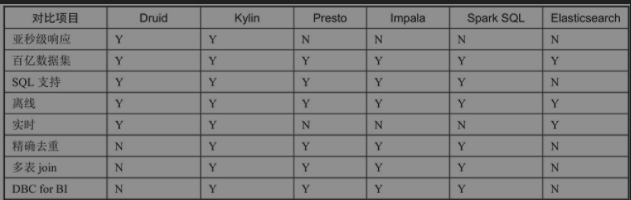
针对上表的对比情况,分析汇总如下。
● Druid:实时处理时序数据的OLAP数据库,因为它的索引首先按照时间进行分片,查询的时候也是按照时间线去路由索引的。
● Kylin:核心是Cube,Cube是一种预计算技术,基本思路是预先对数据进行多维索引,查询时只扫描索引而不访问原始数据,从而提高查询速度。
● Presto:它没有使用MapReduce,大部分场景下比Hive快一个数量级,其中的关键是所有的处理都在内存中完成。
● Impala:基于内存运算,速度快,支持的数据源没有Presto多。
● Spark SQL:基于Spark平台上的一个OLAP框架,基本思路是增加机器以实现并行计算,从而提高查询速度。
● Elasticsearch:最大的特点是使用倒排索引解决了索引存在的问题。根据研究,Elasticsearch在数据获取和聚集时用的资源比在Druid中高。框架选型如下。
● 从超大数据的查询效率来看:Druid > Kylin > Presto >Spark SQL。
● 从支持的数据源种类来看:Presto > Spark SQL > Kylin >Druid。
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
