SparkStreaming Direct方式读取kafka优缺点及示例(Redis保存offset)
在Spark1.3之后,引入了Direct方式。不同于Receiver的方式,Direct方式没有Receiver这一层,其会周期性地获取Kafka中每个topic(主题)的每个partition(分区)中的最新offsets(偏移量),之后根据设定的maxRatePerPartition来处理每个batch。其形式如下图所示。
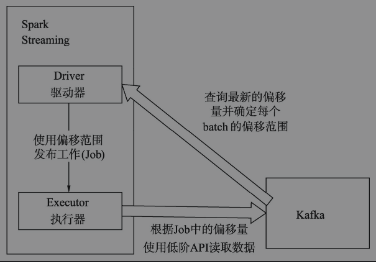
这种方法相较于Receiver方式的优势在于:
● 简化的并行。Direct方式中,Kafka中的partition与Spark内部的partition是一一对应的,这点使得我们可以很容易地通过增加Kafka中的partition来提高数据整体传输的并行度,而不像Receiver方式中还需要创建多个Receiver然后利用union再合并成统一的Dstream。
● 高效。Direct方式中,我们可以自由地根据offset来从Kafka中拉取想要的数据(前提是Kafka保留了足够长时间的数据),这对错误恢复提供了很好的灵活性。然而在Receiver的方式中,还需要将数据存入Write Ahead Log中,存在数据冗余的问题。
● 一次性接收精确的数据记录Direct方式中我们直接使用了低阶Kafka的API接口,offset默认会利用Spark Steaming的checkpoints来存储,同样也可以将其存到数据库等其他地方。然而在Receiver的方式中,由于使用了Kafka的高阶API接口,其默认是从ZooKeeper中拉取offset记录(通常Kafka取数据都是这样的),但是Spark Streaming消费数据的情况和ZooKeeper记录的情况是不同步的,当程序发生中断或者错误时,可能会造成数据重复消费的情况。
不同于Receiver的方式,是从Zookeeper中读取offset值,那么自然Zookeeper就保存了当前消费的offset值,如果重新启动开始消费就会接着上一次offset值继续消费。而在Direct的方式中,是直接从Kafka来读数据,offset需要自己记录,可以利用checkpoint、数据库或文件记录或者回写到ZooKeeper中进行记录。这里我们给出利用Kafka底层API接口,将offset及时同步到ZooKeeper的通用类中。下面示范用redis保存offset
object Demo {
val IP_RANG: Array[String] = "91,92,93,94,95".split(",")
val PORT_RANG: Array[String] = "22420,22421,22422,22423,22424,22425,22426,22427".split(",")
val hosts = new util.HashSet[HostAndPort]()
val sdf:SimpleDateFormat = new SimpleDateFormat("yyyyMMddHHmmss")
def main(args: Array[String]) {
val Array(checkPointDir, topic, brokers, groupId, cf, offset, dw_all_tn, dw_track_tn, dw_unique_tn, batchIntervel) = args
login
val client: JedisCluster = new JedisCluster(hosts, 5000)
var topicPartitions: Map[TopicPartition, Long] = Map()
if (client.exists(topic)) {
val offsetMap: util.Map[String, String] = client.hgetAll(topic)
val iterator: util.Iterator[String] = offsetMap.keySet().iterator()
while (iterator.hasNext) {
val key: String = iterator.next()
val value: String = offsetMap.get(key)
println(key + "------" + value)
topicPartitions += (new TopicPartition(topic, key.toInt) -> value.toLong)
}
}
client.close()
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> brokers,
"value.deserializer" -> classOf[StringDeserializer],
"key.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"security.protocol" -> "SASL_PLAINTEXT",
"sasl.kerberos.service.name" -> "kafka",
"auto.offset.reset" -> offset,
"kerberos.domain.name" -> "hadoop.hadoop.com",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
def functionToCreateContext(): StreamingContext = {
// val topicArr = topic.split(",")
// val topicSet = topicArr.toSet
val locationStrategy = LocationStrategies.PreferConsistent
// val consumerStrategy = ConsumerStrategies.Subscribe[String, String](topicSet, kafkaParams)
val sparkConf: SparkConf = new SparkConf().setAppName("jingyi_xn_dw_all&track")
val ssc = new StreamingContext(sparkConf, Seconds(batchIntervel.toInt))
// if (!"nocp".equals(checkPointDir)) {
// ssc.checkpoint(checkPointDir)
// }
val config = HBaseConfiguration.create()
val hbaseContext = new HBaseContext(ssc.sparkContext, config)
val stream = KafkaUtils.createDirectStream[String, String](ssc,
locationStrategy,
// consumerStrategy
ConsumerStrategies.Assign[String, String](topicPartitions.keys.toList, kafkaParams, topicPartitions)
)
}
}
def setRedisHost: Unit ={
for (host <- IP_RANG) {
for (port <- PORT_RANG) {
hosts.add(new HostAndPort("192.68.196." + host, port.toInt))
}
}
}
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
