Flume案例研究:接收Twitter数据
问题陈述
在此案例研究中,将flume代理配置为从Twitter检索数据。我们知道,Twitter是巨大的数据来源,具有人们的意见和偏好。数据可用于分析舆论或对特定主题或产品进行评论。基于推文数据和位置可以进行各种类型的分析。来自flume的数据可用于通过Streaming API使用Apache Spark进行实时处理。 Spark Streaming用于使用各种数据源(例如Kafka,Flume或TCP套接字)处理实时数据。它还支持Twitter流API。通过使用Flume,我们可以构建一个容错系统,该系统提供实时数据并将数据的副本保存在所需的位置。 Spark还内置了机器学习算法,可以使分析更快,更可靠且具有容错能力。
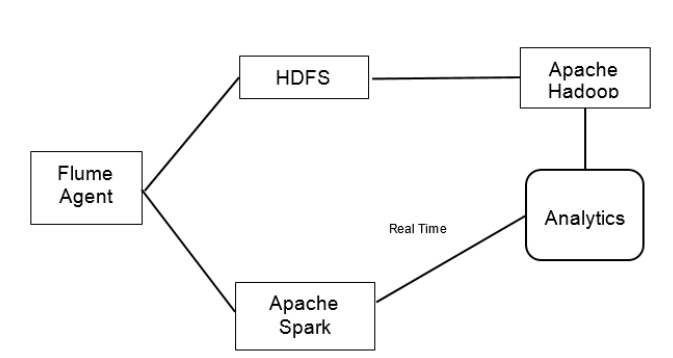
这样,我们可以使用Spark实时获取所需的结果,并将数据存储在数据库中,以便使用Hadoop进行更深入的分析。现在,我们构建一个简单的flume代理,该代理具有Twitter源和接收器,Spark可通过接收器进行数据检索。为了防止数据丢失,我们将使用自定义接收器构建flume代理。即使spark产生故障,由于数据传输中的事务处理功能,数据仍保留在通道中。
拟议的解决方案
现在,必须为我们架构中的各种重要组件设置配置。这样的组件之一就是被配置为从Twitter读取数据的源。源为“ source_read”的flume代理“ agent1”已配置为自定义类型源。为了访问数据,通过注册应用程序,twitter提供了凭证,用户可以使用凭证来检索数据。如果我们需要包含这些单词的特定推文,我们也可以设置关键字。在对特定主题或产品进行分析时,这非常有用。
Cloudera提供了必须包含在Flume类路径中的jar文件才能访问这些类。可以通过在“ flume-env.sh”配置文件中添加jar的路径来完成。如果需要设置其他参数(例如代理),则必须使用源代码重新构建jar。
agent1.sources.source_read.type =
com.cloudera.flume.source.TwitterSource
agent1.sources.source_read.channels = MemChannel
agent1.sources.source_read.consumerKey =
agent1.sources.source_read.consumerSecret =
agent1.sources.source_read.accessToken =
agent1.sources.source_read.accessTokenSecret =
agent1.sources.source_read.keywords = hadoopchannel的配置如下:
agent1.channels.memory1.type = memory
agent1.channels.memory1.capacity = 1000
agent1.channels.memory1.transactionCapacity = 100使用参数“ type”传递自定义sink的代码。 代码的jar文件必须添加到flume类路径中。 定义了spark的IP地址和端口。
agent1.sinks = spark_dump
agent1.sinks.spark_dump.type = org.apache.spark.streaming.flume.sink.SparkSink agent1.sinks.spark_dump.hostname =
agent1.sinks.spark_dump.port =
agent1.sinks.spark_dump.channel = memory1启动flume:
$ bin/flume-ng agent -n $agent_name -c conf -f
conf/flume-conf.properties.template关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
