怎样在3分钟内安装PySpark 和 Jupyter Notebook
对于大数据爱好者来说,Apache Spark是必须的。简而言之,Spark是一个快速而强大的框架,它提供了一个API,可以对弹性数据集执行大规模的分布式处理。 Jupyter Notebook是一个流行的应用程序,它使您可以编辑,运行并将Python代码共享到Web视图中。它允许您以非常灵活的方式修改和重新执行部分代码。因此,Jupyter是测试程序和原型的好工具。 Jupyter Notebook运行Python代码 Jupyter Notebook运行Python代码 我为Linux用户撰写了这篇文章,但是我确信Mac OS用户也可以从中受益。 为什么在Jupyter Notebook中使用PySpark? 使用Spark时,大多数数据工程师建议使用Scala(这是“本机” Spark语言)或通过完整的PySpark API使用Python开发。 Python for Spark显然比Scala慢。但是,像许多开发人员一样,我喜欢Python,因为Python灵活,健壮,易学并且可以从我所有的收藏夹库中受益。我认为,Python是大数据/机器学习领域中进行原型开发的理想语言。 现在,让我们开始吧。
安装pySpark
在安装pySpark之前,必须先安装Python和Spark。 我在以下示例中使用的是Python 3,但您可以轻松地使其适应Python2。请访问Python官方网站进行安装。 我也鼓励您建立一个virtualenv
要安装Spark,请确保您的计算机上安装了Java 8或更高版本。 然后,访问Spark下载页面。 选择最新的Spark版本(一个针对Hadoop的预构建包),然后直接下载。
解压缩并将其移动到您的/ opt文件夹:
$ tar -xzf spark-1.2.0-bin-hadoop2.4.tgz
$ mv spark-1.2.0-bin-hadoop2.4 /opt/spark-1.2.0创建一个软连接
$ ln -s /opt/spark-1.2.0 /opt/spark̀这样,您将能够下载和使用多个Spark版本。 最后,告诉您的bash(或zsh等)在哪里可以找到Spark。 为此,通过在〜/ .bashrc(或〜/ .zshrc)文件中添加以下几行来配置$ PATH变量:
安装Jupyter Notebook
$ pip install jupyter
$ jupyter notebook您在Spark上的第一个Python程序
让我们检查是否在没有先使用Jupyter Notebook的情况下正确安装了PySpark。
您可能需要重新启动终端才能运行PySpark
import random
num_samples = 100000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
sc.stop()Jupyter使用PySpark
有两种方法可以在Jupyter Notebook中使用PySpark:
配置PySpark驱动程序以使用Jupyter Notebook:运行pyspark将自动打开Jupyter Notebook
加载常规的Jupyter Notebook并使用findSpark软件包加载PySpark
第一种选择更快,但特定于Jupyter Notebook,第二种选择是一种更广泛的方法,可以在您喜欢的IDE中使用PySpark。
方法1 —配置PySpark驱动程序
更新PySpark驱动程序环境变量:将这些行添加到〜/ .bashrc(或〜/ .zshrc)文件中。
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'重启并加载:
$ pyspark现在,此命令应在您的Web浏览器中启动Jupyter Notebook。 通过单击“新建”>“ Notebooks Python [默认]”来创建一个新笔记本。
复制并粘贴我们的Pi计算脚本,然后按Shift + Enter运行它。
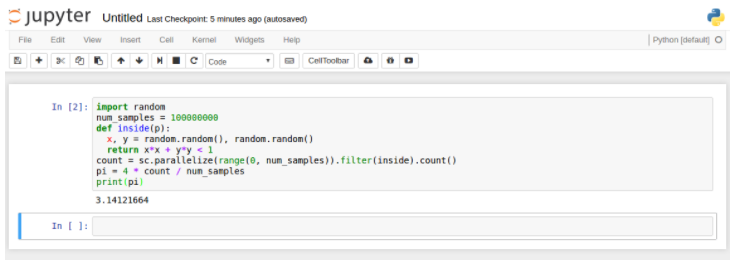
方法2 — FindSpark程序包
在Jupyter Notebook中使用PySpark还有另一种更通用的方法:使用findSpark包在代码中提供Spark上下文。
findSpark包并非特定于Jupyter Notebook,您也可以在自己喜欢的IDE中使用此技巧。
要安装findspark:
$ pip install findspark
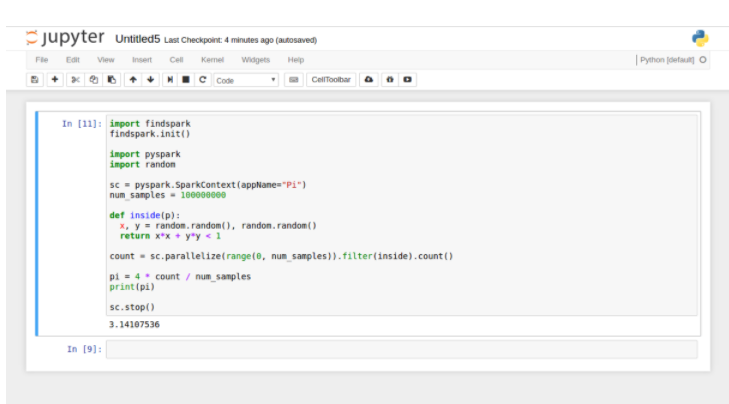
$ jupyter notebook创建一个新的Python [default]笔记本并编写以下脚本:
import findspark
findspark.init()
import pyspark
import random
sc = pyspark.SparkContext(appName="Pi")
num_samples = 100000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
sc.stop()输出结果:
关注公众号“大模型全栈程序员”回复“小程序”获取1000个小程序打包源码。更多免费资源在http://www.gitweixin.com/?p=2627
