从基础的道路通行状态统计、分析、聚类等维度开展对某个城市道路拥堵情况的分析和研究。
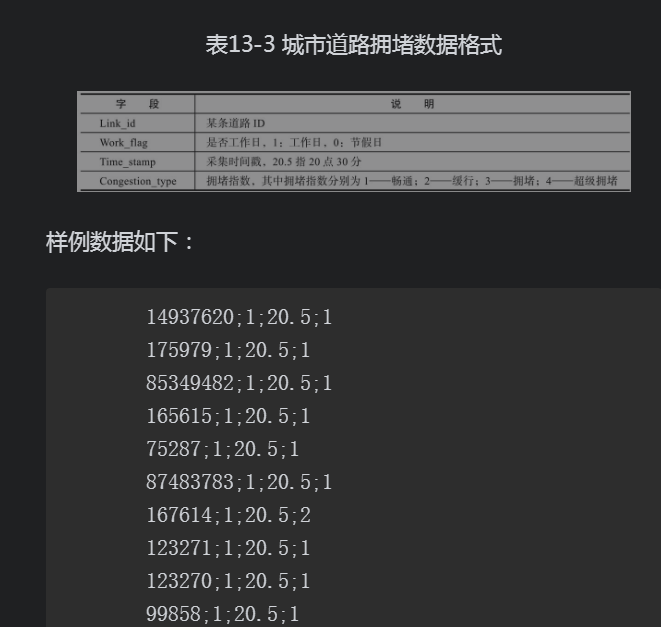
13.3.2 数据预处理根据给定的某地图路况数据,首先进行数据预处理工作,清洗原始数据并去除缺失数据、错误数据,根据道路ID进行数据汇集,计算拥堵指数。1)清除缺失数据:清除字段为空记录;
2)清除错误数据:清除字段错误记录;
3)根据道路ID进行道路拥堵指数聚合;
4)根据时间进行道路拥堵指数排序。
13.3.3 特征构建仍然以半小时为最小时间粒度(每日24小时划分为48维时间片),并对道路拥堵指数按时间片进行聚合计算,同时按照48维时间片进行拥堵指数排列。具体处理过程以及代码如下:
package com.koala.ch13
import org.apache.spark.{SparkConf, SparkContext}
import java.text.SimpleDateFormat
import java.util.Calendar
import breeze.linalg.Counter
import org.apache.log4j.{Level, Logger}
object CrowdModel {
def main(args: Array[String]){
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
if (args.length < 2) {
System.err.println("Usage:CrowdModel <InPath> <OutPut> <Model>")
System.exit(1)
}
// 2rd_data/ch13/user_location_sample.txt output/ch13/CrowdModel local[2]
val Array(input,output,mode) = args
//初始化SparkContext
val conf = new SparkConf()
.setMaster(mode)//.setMaster("local")
.setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
// 位置筛选
// 清洗数据,通过split(",")切分数据,得到 User_id Time_stamp Cell_id三个维度的数据列表。
// (Time_stamp,Cell_id,User_id)-> (User_id,Time_stamp,Cell_id)
// 20160501055052,209059,898
val data = sc.textFile(input).map(_.split(",")).map {
x => (x(2), x(0), x(1))
}
//data.coalesce(1).saveAsTextFile(output)
// 根据Time_stamp分析当前日期为工作日或节假日,并添加time标签标识HH:mm,work_flag标签标识工作日(work_falg=1)或节假日(work_flag=0)
// 输出:(User_id,work_flag,date_time,Cell_id)
val preData = data.map {
case (preUser_id, preTime_stamp, preCell_id) => {
//将日期转变成星期,获取工作日(星期一至星期五)和非工作日(星期六、星期日)
// 20160501 055052
val sdf = new SimpleDateFormat("yyyyMMddHHmmss") //24小时工作制
val date = sdf.parse(preTime_stamp)
val cal = Calendar.getInstance
cal.setTime(date)
var w = cal.get(Calendar.DAY_OF_WEEK) - 1
// 工作日默认为1 非工作日默认为0
var work_flag = 1
if (w <= 0 || w >= 6) {
work_flag = 0
}
// 按照30分钟间隔处理时间
val time_ = preTime_stamp.substring(8, 12)
// 截取指定位置的元素,前包括后不包括
var minute_ = "00"
if (time_.substring(2).toInt >= 30) {
minute_ = "30"
}
val date_time = time_.toString.substring(0, 2) + minute_
((preUser_id, work_flag, date_time, preCell_id), 1)
}
}
//preData.coalesce(1).saveAsTextFile(output)
//使用reduceByKey(_+_)对(User_id,work_flag,date_time,Cell_id)访问次数进行聚合,根据聚合结果,选择用户某段时间在30分钟内划分访问次数最多的基站为标准访问地点。
val aggData = preData.reduceByKey(_ + _)
.map { x => ((x._1._1, x._1._2, x._1._3), (x._1._4, x._2)) }
.reduceByKey((a, b) => if (a._2 > b._2) a else b)//选取访问次数最多的cell
//aggData.coalesce(1).saveAsTextFile(output)
//获取用户工作日24小时访问地点cell_id、节假日24小时访问地点cell_id,以30分钟为最小时间粒度划分时间片,得到user_id工作日48维时间片访问cell_id和节假日48维时间片访问cell_id,共计96维时间片。
//(User_id,work_flag,date_time),(Cell_id,nums)->(User_id,work_flag),(date_time,Cell_id)
val slotData = aggData.map { x => ((x._1._1, x._1._2), (x._1._3 + ":" + x._2._1)) }.reduceByKey(_ + ";" + _)
//slotData.coalesce(1).saveAsTextFile(output)
// 位置编码
// 根据聚合结果,提取所有用户访问的基站进行重新编码,获得用户访问位置列表cell_id,并进行排序去重
// (User_id,work_flag,date_time),(Cell_id,nums)
val minCell = aggData.map(x => x._2._1).sortBy(x=>x.toLong,true).collect().distinct
println(minCell.toList)
//使用zip方法从1开始对用户访问地址进行编码,并将编码进行保存。
val index_list = minCell.zip(Stream from 1).toMap
println(index_list)
//得到的index_list即是用户访问位置编码特征向量。
}
}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkConf, SparkContext}
object CleanCongestionData {
def main(args: Array[String]) {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
if (args.length < 2) {
System.err.println("Usage:CleanCongestionData <InPath> <OutPut> <Model>")
System.exit(1)
}
// 2rd_data/ch13/road_congestion_sample.txt output/ch13/CongestionModel local[2]
val Array(input,output,mode) = args
// 初始化SparkContext
val conf = new SparkConf()
.setMaster(mode)//.setMaster("local")
.setAppName(this.getClass.getSimpleName)
val sc = new SparkContext(conf)
// 计算link的拥堵情况,指定道路、工作日状态、时间片时,link拥堵指数的平均值(四舍五入)取整,
// key (linkid, work_flag, hour) value (congestion)
// 85349482;1;20.5;1
val data = sc.textFile(input).map(_.split(";"))
.map {x => ((x(0),x(1),x(2)),x(3))}
.groupByKey().mapValues(x=>{
val a = x.toList.reduceLeft((sum,i)=>sum +i)//拥堵指数求和
val b = x.toList.length
Math.round(a.toInt/b)//平均拥堵指数
})
//data.coalesce(1).saveAsTextFile(output)
// 根据key聚合数据后,使用hour 进行排序 并删除hour数据
// key (linkid,work_flag, hour) value (congestion)->(linkid) value(work_flag,congestion)
val collectData = data.sortBy(x=>x._1._3).map(x => ((x._1._1),(x._1._2+":"+x._2))).reduceByKey(_ + ";" + _)
collectData.coalesce(1).saveAsTextFile(output)
}
}