订阅-通知是视图库接口最核心的业务,也是大华和友商使用最频繁的一个功能。本节将描述完整的一个订阅-通知流程。
订阅通知过程本质是数据转移,例如A想通过视图库获得B的机动车数据,那么A就是上级、B就是下级;假如A想通过B间接获得C的机动车数据,那么A就是B的上级,B是C的上级,这个过程为跨级订阅/通知。
订阅-通知流程见图2:
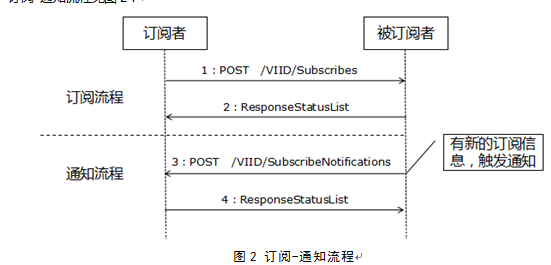
图2 订阅-通知流程
Step1:订阅者(上级)向被订阅者(下级)发送HTTP
POST请求/VIID/Subscribes。
Step2:被订阅者(下级)将订阅成功与否的响应消息返回给订阅者(上级)。
订阅成功后,被订阅者(下级)如果有订阅信息,便会进行通知任务。
Step3:被订阅者(下级)向订阅者(上级)发送HTTP POST请求/VIID/SubscribeNotifications。
Step4:订阅者(上级)返回响应消息。
Step5:被订阅者(下级)接收到Step4订阅者(上级)正确返回结果才会再重复Step3,4的操作,如此循环。
如果订阅者想取消订阅,流程如图3:

图3 取消订阅流程
Step1:订阅者(上级)可以向被订阅者(下级)发送HTTP PUT请求/VIID/Subscribes/<ID>,写入订阅取消单位、订阅取消人、取消时间、取消原因。
Step2:被订阅者(下级)将取消订阅成功与否的响应消息返回给订阅者(上级)。
Step3:取消订阅成功后对应的通知流程将终止。
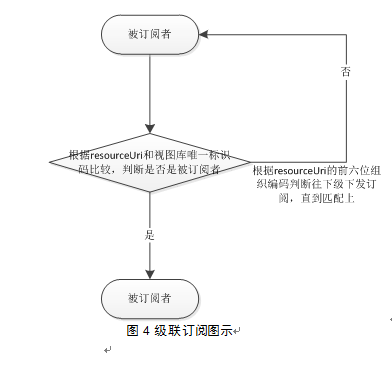
批量订阅
1.接口概览
|
URI
|
/VIID/Subscribes
|
|
方法
|
查询字符串
|
消息体
|
返回结果
|
|
POST
|
无
|
<SubscribeList>
|
<ResponseStatusList>
|
|
备注
|
|
2.消息体特征参数
消息体结构参考C.19,字段定义参考A.19 。
3.返回结果
结构参考C.25,字段定义参考A.26。
4.示例
|
URI
|
/VIID/Subscribes
|
|
请求方法
|
POST
|
|
请求头
|
参见请求参数
|
|
请求体
|
{
“SubscribeListObject”: {
“SubscribeObject”: [
{
“SubscribeID”:
“330101020001032017113010580006371”,
“ApplicantName”:
“admin”,
“ApplicantOrg”:
“11111”,
“BeginTime”:
“20171201000000”,
“EndTime”:
“20191230000000”,
“OperateType”:
“0”,
“Reason”: “测试”,
“ReceiveAddr”:
“http://172.6.3.107:80/VIID/SubscribeNotifications”,
“ResourceURI”:
“00330102015030000004”,
“SubscribeDetail”:
“13”,
“Title”: “过车”
}
]
}
}
|
|
响应体
|
{
“ResponseStatusListObject”:
{
“ResponseStatusObject”: [
{
“RequestURL”:
“http://localhost:8080/VIID/Subscribes”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“330101020001032017113010580006371”,
“LocalTime”: “20171220204451”
}
]
}
}
|
订阅任务查询
1.接口概览
|
URI
|
/VIID/Subscribes
|
|
方法
|
查询字符串
|
消息体
|
返回结果
|
|
GET
|
Subscribes属性键-值对
|
无
|
<SubscribeList>
|
|
备注
|
|
2.查询字符串
查询指令为Subscribes属性键-值对,特征属性定义参考A.19 。
3.返回结果
结构参考C.19,字段定义参考A.19。
4.示例
|
URI
|
/VIID/Subscribes
|
|
请求方法
|
GET
|
|
请求头
|
参见请求参数
|
|
查询参数
|
?SubscribeID=330101020001032017113010580006371
&ApplicantName=admin
&ApplicantOrg=11111
&BeginTime=20171201000000
&EndTime=20191230000000&…
|
|
响应体
|
{
“SubscribeListObject”: {
“SubscribeObject”: [
{
“SubscribeID”:
“330101020001032017113010580006371”,
“ApplicantName”:
“admin”,
“ApplicantOrg”:
“11111”,
“BeginTime”:
“20171201000000”,
“EndTime”:
“20191230000000”,
“OperateType”: “0”,
“Reason”: “测试”,
“ReceiveAddr”:
“http://172.6.3.107:80/VIID/SubscribeNotifications”,
“ResourceURI”:
“00330102015030000004”,
“SubscribeDetail”:
“13”,
“Title”: “过车”
}
]
}
}
|
订阅任务修改
1.接口概览
|
URI
|
/VIID/Subscribes
|
|
方法
|
查询字符串
|
消息体
|
返回结果
|
|
PUT
|
无
|
<SubscribeList>
|
<ResponseStatusList>
|
|
备注
|
消息体中SubscribeID必填,否则操作无效
|
2.消息体特征参数
消息体结构参考C.19,字段定义参考A.19 。
3.返回结果
结构参考C.25,字段定义参考A.26。
4.示例
|
URI
|
/VIID/Subscribes
|
|
请求方法
|
PUT
|
|
请求头
|
参见请求参数
|
|
请求体
|
{
“SubscribeListObject”: {
“SubscribeObject”: [
{
“SubscribeID”:
“330101020001032017113010580006371”,
“ApplicantName”:
“admin”,
“ApplicantOrg”:
“11111”,
“BeginTime”:
“20171201000000”,
“EndTime”:
“20191230000000”,
“OperateType”:
“0”,
“Reason”: “上下级汇聚”,
“ReceiveAddr”:
“http://172.6.3.107:80/VIID/SubscribeNotifications”,
“ResourceURI”:
“00330102015030000004”,
“SubscribeDetail”:
“13”,
“Title”: “过车测试”
}
]
}
}
|
|
响应体
|
{
“ResponseStatusListObject”: {
“ResponseStatusObject”: [
{
“RequestURL”:
“http://localhost:8080/VIID/Subscribes”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“330101020001032017113010580006371”,
“LocalTime”: “20171220204451”
}
]
}
}
|
1.接口概览
|
URI
|
/VIID/Subscribes
|
|
方法
|
请求参数
|
消息体
|
返回结果
|
|
DELETE
|
键为IDList,值为用英文半角分号”,”分隔的字符串
|
无
|
<ResponseStatusList>
|
|
备注
|
|
2.请求参数
IDList=<SubscribeID>,<SubscribeID>。
3.返回结果
结构参考C.25,字段定义参考A.26。
4.示例
|
URI
|
/VIID/Subscribes
|
|
请求方法
|
DELETE
|
|
请求头
|
参见请求参数
|
|
请求参数
|
?IDList=330101020001032017113010580006371,330101020001032017113010580006372
|
|
响应体
|
{
“ResponseStatusListObject”: {
“ResponseStatusObject”: [
{
“RequestURL”:
“http://localhost:8080/VIID/Subscribes”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“330101020001032017113010580006371”,
“LocalTime”: “20171220204451”
},
{
“RequestURL”:
“http://localhost:8080/VIID/Subscribes”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“330101020001032017113010580006372”,
“LocalTime”: “20171220204451”
}
]
}
}
|
取消订阅
1.接口概览
|
URI
|
/VIID/Subscribes/<ID>
|
|
方法
|
请求参数
|
消息体
|
返回结果
|
|
PUT
|
无
|
<Subscribe>
|
<ResponseStatus>
|
|
备注
|
PUT更新Subscribe写入订阅取消单位、订阅取消人、取消时间、取消原因。
|
2.消息体特征参数
订阅对象中的取消单位、订阅取消人、取消时间、取消原因,字段定义参考A.19。
3.返回结果
结构参考C.25,字段定义参考A.26。
4.示例
|
URI
|
/VIID/Subscribes/330101020001032017113010580006371
|
|
请求方法
|
PUT
|
|
请求头
|
参见请求参数
|
|
消息体
|
{
“SubscribeObject”: {
“SubscribeCancelOrg”:
“省公安厅”,
“SubscribeCancelPerson”:
“admin”,
“CancelTime”:
“20171201000000”,
“CancelReason”: “服务到期”
}
}
|
|
响应体
|
{
“ResponseStatusObject”: {
“RequestURL”:
“http://localhost:8080/VIID/Subscribes/330101020001032017113010580006371”,
“StatusCode”: 0,
“StatusString”:
“正常”,
“Id”:
“330101020001032017113010580006371”,
“LocalTime”:
“20171220204451”
}
}
|
订阅通知
1.接口概览
|
URI
|
/VIID/SubscribeNotifications
|
|
方法
|
查询字符串
|
消息体
|
返回结果
|
|
POST
|
无
|
<SubscribeNotificationList>
|
<ResponseStatusList>
|
|
备注
|
|
2.消息体特征参数
消息体结构参考C.20,字段定义参考A.20。
3.返回结果
结构参考C.25,字段定义参考A.26。
4.示例
|
URI
|
/VIID/SubscribeNotifications
|
|
请求方法
|
POST
|
|
请求头
|
参见请求参数
|
|
请求体
|
{
“SubscribeNotificationListObject”: {
“SubscribeNotificationObject”: [
{
“NotificationID”:
“650100010000042017040112010100001”,
“Title”: “通知主题”,
“SubscribeID”:
“650100010000032017040112010100001”,
“TriggerTime”:
“20171102101205”,
“InfoIDs”:
“650100000013200000010120170330120000000010100001”,
“DeviceList”: {
“APEObject”: [
{
“Name”:
“这是一个采集设备”,
“Port”:
8888,
“Password”: “p@ssword”,
“Model”: “这是采集设备的型号”,
“ApeID”: “65010000001190000001”,
“MonitorAreaDesc”:
“监控区域说明”,
“IPAddr”: “192.168.1.1”,
“IPV6Addr”: “fe80::69fd:1871:b9ba:24e7%13”,
“Longitude”: 56.654321,
“Latitude”: 56.123456,
“PlaceCode”:
“650100”,
“OrgCode”: “650100010000”,
“CapDirection”: 1,
“MonitorDirect”: “1”,
“IsOnline”: “1”,
“OwnerApsID”:
“65010000001200000001”,
“UserId”: “Administrator”,
“Place”: “新疆乌鲁木齐”
}
]
}
}
]
}
}
|
|
响应体
|
{
“ResponseStatusListObject”: {
“ResponseStatusObject”: [{
“RequestURL”:
“http://localhost:8080/VIID/SubscribeNotifications”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“330101020001032017113010580006371”,
“LocalTime”: “20171220204451”
}
]}
}
|
通知查询
1.接口概览
|
URI
|
/VIID/SubscribeNotifications
|
|
方法
|
查询字符串
|
消息体
|
返回结果
|
|
GET
|
SubscribeNotifaication属性键-值对
|
无
|
<SubscribeNotificationList>
|
|
备注
|
|
2.查询字符串
查询指令为SubscribeNotifications属性键-值对,特征属性定义参考A.20。
3.返回结果
结构参考C.20,字段定义参考A.20。
4.示例
|
URI
|
/VIID/SubscribeNotifications
|
|
请求方法
|
GET
|
|
请求头
|
参见请求参数
|
|
查询参数
|
?NotificationID=650100010000042017040112010100001
&Title=通知主题&…
|
|
响应体
|
{
“SubscribeNotificationListObject”: {
“SubscribeNotificationObject”: [
{
“NotificationID”:
“650100010000042017040112010100001”,
“Title”: “通知主题”,
“SubscribeID”:
“650100010000032017040112010100001”,
“TriggerTime”:
“20171102101205”,
“InfoIDs”:
“650100000013200000010120170330120000000010100001”,
“DeviceList”: {
“APEObject”: [
{
“Name”:
“这是一个采集设备”,
“Port”:
8888,
“Password”: “p@ssword”,
“Model”: “这是采集设备的型号”,
“ApeID”: “65010000001190000001”,
“MonitorAreaDesc”: “监控区域说明”,
“IPAddr”: “192.168.1.1”,
“IPV6Addr”: “fe80::69fd:1871:b9ba:24e7%13”,
“Longitude”:
56.654321,
“Latitude”: 56.123456,
“PlaceCode”: “650100”,
“OrgCode”: “650100010000”,
“CapDirection”: 1,
“MonitorDirect”:
“1”,
“IsOnline”: “1”,
“OwnerApsID”: “65010000001200000001”,
“UserId”: “Administrator”,
“Place”: “新疆乌鲁木齐”
}
]
}
}
]
}
}
|
通知删除
1.接口概览
|
URI
|
/VIID/SubscribeNotifications
|
|
方法
|
请求参数
|
消息体
|
返回结果
|
|
DELETE
|
键为IDList,值为用英文半角分号”,”分隔的字符串
|
无
|
<ResponseStatusList>
|
|
备注
|
|
2.请求参数
IDList=<NotificationID>,<NotificationID>。
3.返回结果
结构参考C.20,字段定义参考A.20。
4.示例
|
URI
|
/VIID/SubscribeNotifications
|
|
请求方法
|
DELETE
|
|
请求头
|
参见请求参数
|
|
请求参数
|
?IDList=650100010000042017040112010100001,650100010000042017040112010100002
|
|
响应体
|
{
“ResponseStatusListObject”: {
“ResponseStatusObject”: [
{
“RequestURL”:
“http://localhost:8080/VIID/SubscribeNotifications”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“650100010000042017040112010100001”,
“LocalTime”: “20171220204451”
},
{
“RequestURL”:
“http://localhost:8080/VIID/SubscribeNotifications”,
“StatusCode”: 0,
“StatusString”: “正常”,
“Id”:
“650100010000042017040112010100002”,
“LocalTime”: “20171220204451”
}
]
}
}
|
//订阅对象
<complexType
name=”Subscribe”>
<sequence>
<element
name=”SubscribeID” type=”BusinessObjectIdType”/>
<element
name=”Title” type=”string” />
<element name=” SubscribeDetail” type=” SubscribeDetailType”/>
<element
name=” ResourceURI” type=” string”/>
<element
name=”ApplicantName” type=”NameType” />
<element
name=”ApplicantOrg” type=”OrgType”
/>
<element
name=”BeginTime” type=”dateTime” />
<element
name=”EndTime” type=”dateTime” />
<element
name=”ReceiveAddr” type=”string”
/>
<element
name=”OperateType” type=”int” use=”required”/>
<element
name=”SubscribeStatus” type=”int” />
<element
name=”Reason” type=”string”/>
<element
name=”SubscribeCancelOrg” type=”OrgType”/>
<element
name=”SubscribeCancelPerson” type=”string”/>
<element
name=”CancelTime” type=”dateTime”/>
<element
name=”CancelReason” type=”string”/>
</sequence>
</complexType>
//订阅对象列表
<complexType name=”SubscribeList”>
<sequence>
<element name=”SubscribeObject” type=”Subscribe”
minOccurs=”0″ />
</sequence>
</complexType>
C.20 通知对象
//通知对象
<complexType
name=”SubscribeNotification”>
<sequence>
<element
name=”NotificationID” type=”BusinessObjectIdType” use=”required”/>
<element
name=”SubscribeID” type=”BusinessObjectIdType”
use=”required”/>
<element name=”Title” type=”string”
use=”required”/>
<element
name=”TriggerTime” type=”dateTime”
use=”required”/>
<element
name=”InfoIDs” type=”string” use=”required”/>
<element
name=”CaseObjectList” type=”CaseList”/>
<element name=”TollgateObjectList” type=”TollgateList”/>
<element name=”LaneObjectList”
type=”LaneList”/>
<element
name=”DeviceList” type=”APEList”/>
<element
name=”DeviceStatusList” type=”APEStatusList”/>
<element
name=”APSObjectList” type=”APSList”/>
<element
name=”APSStatusObjectList” type=”APSStatusList”/>
<element
name=”PersonObjectList” type=”PersonList”/>
<element
name=”MotorVehicleObjectList” type=”MotorVehicleList”/>
<element name=”NonMotorVehicleObjectList”
type=”NonMotorVehicleList”/>
<element
name=”ThingObjectList” type=”ThingList”/>
<element name=”SceneObjectList”
type=”SceneList”/>
</sequence>
</complexType>
//通知对象列表
<complexType
name=”SubscribeNotificationList”>
<sequence>
<element name=”SubscribeNotificationObject” type=”SubscribeNotification”
minOccurs=”0″ />
</sequence>
</complexType>