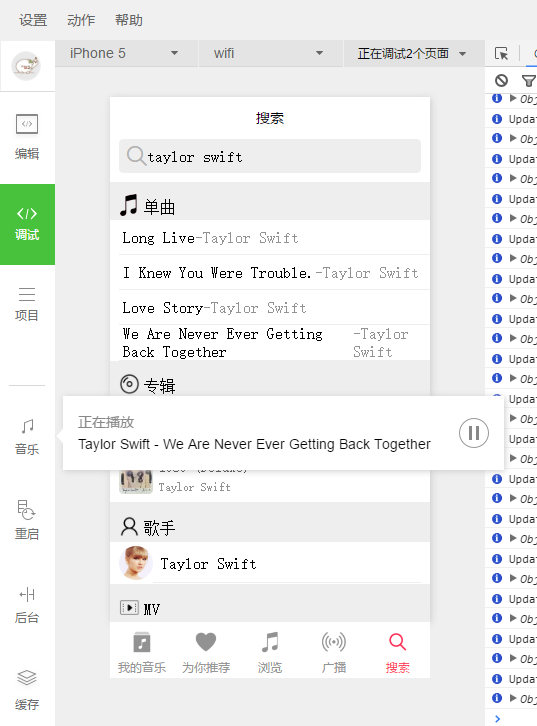
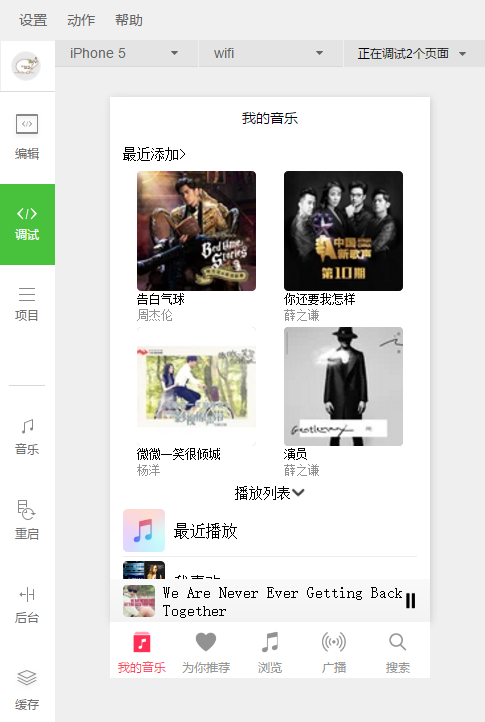
功能有我的音乐、为你推荐、浏览、广播、搜索等功能。
通过本例子,可以学习到全局变量使用。首先对比一下页面中的共享变量是如何设置的。页面的共享变量被设置在页面Page方法的object对象上,比如data就是object对象的一个属性。所以,我们在其他方法中才能够多次使用this.data的方式引用这个data对象。页面的共享变量应该在页面中设置,所以全局共享变量自然应该在应用程序级别设置。小程序提供了一个全局方法getApp(),用于获取小程序的App对象。
var pageObject = {
data: {
playing:false,
playingSongsNum:0,
musicGroupName:items[0],
listTemplateName:'music-play-list',
actionSheetHidden: true,
actionSheetItems: items,
playBar:{
dataUrl:'http://stream.qqmusic.tc.qq.com/137192078.mp3',
name: '告白气球',
singer:'周杰伦',
coverImgUrl: 'http://y.gtimg.cn/music/photo_new/T002R90x90M000003RMaRI1iFoYd.jpg'
},
songsList:_songsList,
albumList :_albumList
},
playButtonTap:function(){
var that = this
},
actionSheetTap: function(e) {
this.setData({
actionSheetHidden: !this.data.actionSheetHidden
})
},
actionSheetChange: function(e) {
this.setData({
actionSheetHidden: !this.data.actionSheetHidden
})
},
onLoad: function () {
var that = this
wx.onBackgroundAudioStop(function () {
that.setData({
playing: false
})
})
},
play: function (event) {
var that = this
var res=that.data.songsList[event.currentTarget.dataset.num]
getApp().globalData.playing = res
that.setData({
playBar:res,
playingSongsNum:event.currentTarget.dataset.num
})
wx.playBackgroundAudio({
dataUrl: res.dataUrl,
name: res.name,
singer:res.singer,
coverImgUrl: res.coverImgUrl,
complete: function (res) {
that.setData({
playing: true
})
}
})
},
pause: function () {
var that = this
wx.pauseBackgroundAudio({
success: function () {
that.setData({
playing: false
})
}
})
},
onUnload: function () {
clearInterval(this.updateInterval)
},
onShow:function(){
var that = this
wx.request({
url: 'http://120.27.93.97/weappserver/get_music.php',
data: {
mid: getApp().globalData.playing.mid
},
header: {
'Content-Type': 'text/html;charset=utf-8'
},
success: function(res) {
console.log(res.data)
var obj=that.data.playBar
obj['coverImgUrl']='http:'+res.data
that.setData({
playBar:obj
})
}
})
that.setData({
playing: true,
playBar: getApp().globalData.playing
})
}
}
for (var i = 0; i < items.length; ++i) {
(function(itemName) {
switch(itemName){
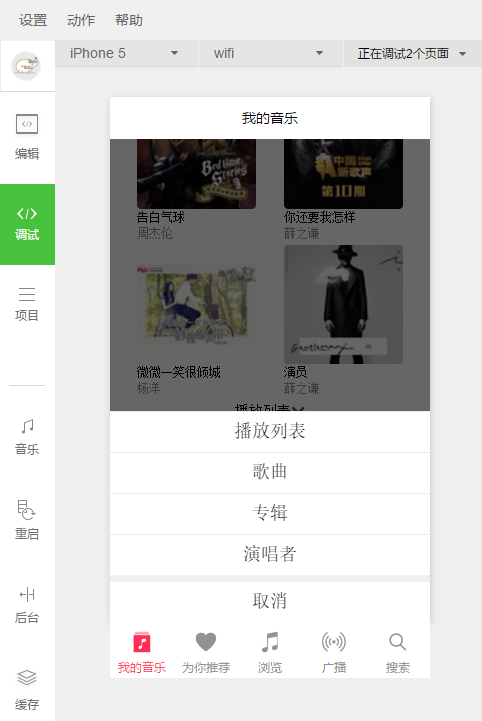
case '播放列表':
pageObject['bind' + itemName] = function(e) {
console.log('click' + itemName, e)
this.setData({
musicGroupName:itemName,
listTemplateName:'music-play-list',
templateData:null,
actionSheetHidden: !this.data.actionSheetHidden
})
}
break;
case '歌曲':
pageObject['bind' + itemName] = function(e) {
console.log('click' + itemName, e)
this.setData({
musicGroupName:itemName,
listTemplateName:'songs-list',
templateData:_songsList,
actionSheetHidden: !this.data.actionSheetHidden
})
}
break;
case '专辑':
pageObject['bind' + itemName] = function(e) {
console.log('click' + itemName, e)
this.setData({
musicGroupName:itemName,
listTemplateName:'album-list',
templateData:_albumList,
actionSheetHidden: !this.data.actionSheetHidden
})
}
break;
case '演唱者':
pageObject['bind' + itemName] = function(e) {
console.log('click' + itemName, e)
this.setData({
musicGroupName:itemName,
listTemplateName:'singer-list',
templateData:null,
actionSheetHidden: !this.data.actionSheetHidden
})
}
break;
}
})(items[i])
}
下载地址:代码