本实例来源于《Spark高级数据分析》,这是一个很好的spark数据挖掘的实例。从经验上讲,推荐引擎属于大规模机器学习,在日常购物中大家或许深有体会,比如:你在淘宝上浏览了一些商品,或者购买了一些商品,那么淘宝就会根据你的偏好给你推荐一些其他类似的商品。然而,相比较其他机器学习算法,推荐引擎的输出更加的直观,有时候的推荐效果让人吃惊。作为机器学习开篇文章,本篇文章会系统的介绍基于Audioscrobbler数据集的音乐推荐。
数据集介绍
Audioscrobbler数据集是一个公开发布的数据集,读者可以在(https://github.com/libaoquan95/aasPractice/tree/master/c3/profiledata_06-May-2005)网站获取。数据集主要有三部分组成,user_artist_data.txt文件是主要的数据集文件记录了约2420条用户id、艺术家id以及用户收听艺术家歌曲的次数数据,包含141000个用户和160万个艺术家;artist_data.txt文件记录了艺术家id和对应的名字;artist_alias.txt记录了艺术家id和对应的别称id。
推荐算法介绍
由于所选取的数据集只记录了用户和歌曲之间的交互情况,除了艺术家名字之外没有其他信息。因此要找的学习算法不需要用户和艺术家的属性信息,这类算法通常被称为协同过滤。如果根据两个用户的年龄相同来判断他们可能具有相似的偏好,这不叫协同过滤。相反,根据两个用户播放过许多相同歌曲来判断他们可能都喜欢某首歌,这是协调过滤。
本篇所用的算法在数学上称为迭代最小二乘,把用户播放数据当成矩阵A,矩阵低i行第j列上的元素的值,代表用户i播放艺术家j的音乐。矩阵A是稀疏的,绝大多数元素是0,算法将A分解成两个小矩阵X和Y,既A=XYT,X代表用户特征矩阵,Y代表特征艺术家矩阵。两个矩阵的乘积当做用户-艺术家关系矩阵的估计。可以通过下边一组图直观的反映:
现在假如有5个听众,音乐有5首,那么A是一个5*5的矩阵,假如评分如下:
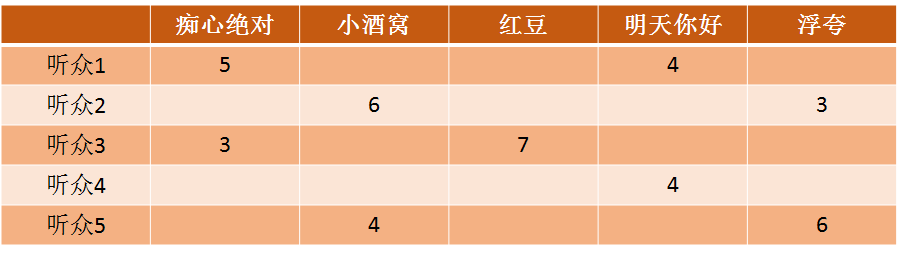
图2.1 用户订阅矩阵
假如d是三个属性,那么X的矩阵如下:
图2.2 用户-特征矩阵
Y的矩阵如下: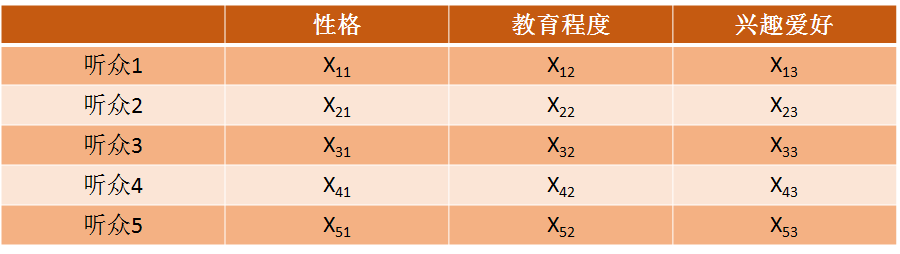
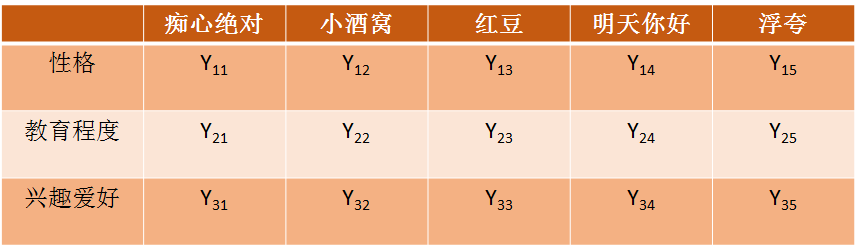
图2.3 特征-电影矩阵
实际的求解过程中通常先随机的固定矩阵Y,则 ,为提高计算效率,通常采用并行计算X的每一行,既
,为提高计算效率,通常采用并行计算X的每一行,既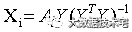 。得到X之后,再反求出Y,不断的交替迭代,最终使得XYT与A的平方误差小于指定阈值,停止迭代,得到最终的X(代表用户特征矩阵)和Y矩阵(代表特征艺术家矩阵)。在根据最终X和Y矩阵结果,向用户进行推荐。
。得到X之后,再反求出Y,不断的交替迭代,最终使得XYT与A的平方误差小于指定阈值,停止迭代,得到最终的X(代表用户特征矩阵)和Y矩阵(代表特征艺术家矩阵)。在根据最终X和Y矩阵结果,向用户进行推荐。
数据准备
首先将样例数据上传到HDFS,如果想要在本地测试这些功能的话,需要内存数量至少 6g, 当然可以通过减少数据量来达到通用的测试。
object RunRecommender {
def main(args: Array[String]): Unit = {
val conf = new SparkConf();
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
// Optional, but may help avoid errors due to long lineage
// spark.sparkContext.setCheckpointDir("hdfs:///tmp/")
spark.sparkContext.setCheckpointDir("d:///tmp/")
//val base = "hdfs:///user/ds/"
val base = "E:/newcode/spark/aas/data/";
val rawUserArtistData = spark.read.textFile(base + "user_artist_data.txt")
val rawArtistData = spark.read.textFile(base + "artist_data.txt")
val rawArtistAlias = spark.read.textFile(base + "artist_alias.txt")
val runRecommender = new RunRecommender(spark)
runRecommender.preparation(rawUserArtistData, rawArtistData, rawArtistAlias)
runRecommender.model(rawUserArtistData, rawArtistData, rawArtistAlias)
runRecommender.evaluate(rawUserArtistData, rawArtistAlias)
runRecommender.recommend(rawUserArtistData, rawArtistData, rawArtistAlias)
}
}
def preparation(
rawUserArtistData: Dataset[String],
rawArtistData: Dataset[String],
rawArtistAlias: Dataset[String]): Unit = {
rawUserArtistData.take(5).foreach(println)
val userArtistDF = rawUserArtistData.map { line =>
val Array(user, artist, _*) = line.split(' ')
(user.toInt, artist.toInt)
}.toDF("user", "artist")
userArtistDF.agg(min("user"), max("user"), min("artist"), max("artist")).show()
val artistByID = buildArtistByID(rawArtistData)
val artistAlias = buildArtistAlias(rawArtistAlias)
val (badID, goodID) = artistAlias.head
artistByID.filter($"id" isin (badID, goodID)).show()
}
/**
* 过滤无效的用户艺术家ID和名字行,将格式不正确的数据行剔除掉。
* @param rawArtistData
* @return
*/
def buildArtistByID(rawArtistData: Dataset[String]): DataFrame = {
rawArtistData.flatMap { line =>
val (id, name) = line.span(_ != '\t')
if (name.isEmpty) {
None
} else {
try {
Some((id.toInt, name.trim))
} catch {
case _: NumberFormatException => None
}
}
}.toDF("id", "name")
}
/**
* 过滤艺术家id和对应的别名id,将格式拼写错误的行剔除掉。
* @param rawArtistAlias
* @return
*/
def buildArtistAlias(rawArtistAlias: Dataset[String]): Map[Int,Int] = {
rawArtistAlias.flatMap { line =>
val Array(artist, alias) = line.split('\t')
if (artist.isEmpty) {
None
} else {
Some((artist.toInt, alias.toInt))
}
}.collect().toMap
}
代码中模型训练好之后,预测了用户 2093760 的推荐结果,我测试结果如下,由于里面代码使用了随机生成初始矩阵,每个人的结果都有可能不一样。
Some((2814,50 Cent))
Some((829,Nas))
Some((1003249,Ludacris))
Some((1001819,2Pac))
Some((1300642,The Game))
代码中也给出了该用户以前听过的艺术家的名字如下:
Some((1180,David Gray))
Some((378,Blackalicious))
Some((813,Jurassic 5))
Some((1255340,The Saw Doctors))
Some((942,Xzibit))
模型评价
auc评价方法
def areaUnderCurve(
positiveData: DataFrame,
bAllArtistIDs: Broadcast[Array[Int]],
predictFunction: (DataFrame => DataFrame)): Double = {
// What this actually computes is AUC, per user. The result is actually something
// that might be called "mean AUC".
// Take held-out data as the "positive".
// Make predictions for each of them, including a numeric score
val positivePredictions = predictFunction(positiveData.select("user", "artist")).
withColumnRenamed("prediction", "positivePrediction")
// BinaryClassificationMetrics.areaUnderROC is not used here since there are really lots of
// small AUC problems, and it would be inefficient, when a direct computation is available.
// Create a set of "negative" products for each user. These are randomly chosen
// from among all of the other artists, excluding those that are "positive" for the user.
val negativeData = positiveData.select("user", "artist").as[(Int,Int)].
groupByKey { case (user, _) => user }.
flatMapGroups { case (userID, userIDAndPosArtistIDs) =>
val random = new Random()
val posItemIDSet = userIDAndPosArtistIDs.map { case (_, artist) => artist }.toSet
val negative = new ArrayBuffer[Int]()
val allArtistIDs = bAllArtistIDs.value
var i = 0
// Make at most one pass over all artists to avoid an infinite loop.
// Also stop when number of negative equals positive set size
while (i < allArtistIDs.length && negative.size < posItemIDSet.size) {
val artistID = allArtistIDs(random.nextInt(allArtistIDs.length))
// Only add new distinct IDs
if (!posItemIDSet.contains(artistID)) {
negative += artistID
}
i += 1
}
// Return the set with user ID added back
negative.map(artistID => (userID, artistID))
}.toDF("user", "artist")
// Make predictions on the rest:
val negativePredictions = predictFunction(negativeData).
withColumnRenamed("prediction", "negativePrediction")
// Join positive predictions to negative predictions by user, only.
// This will result in a row for every possible pairing of positive and negative
// predictions within each user.
val joinedPredictions = positivePredictions.join(negativePredictions, "user").
select("user", "positivePrediction", "negativePrediction").cache()
// Count the number of pairs per user
val allCounts = joinedPredictions.
groupBy("user").agg(count(lit("1")).as("total")).
select("user", "total")
// Count the number of correctly ordered pairs per user
val correctCounts = joinedPredictions.
filter($"positivePrediction" > $"negativePrediction").
groupBy("user").agg(count("user").as("correct")).
select("user", "correct")
// Combine these, compute their ratio, and average over all users
val meanAUC = allCounts.join(correctCounts, Seq("user"), "left_outer").
select($"user", (coalesce($"correct", lit(0)) / $"total").as("auc")).
agg(mean("auc")).
as[Double].first()
joinedPredictions.unpersist()
meanAUC
}
完整代码下载:RunRecommender.scala