接手别人开发的spark程序,大概弄懂整个流程,但一些细节总是猜不透,在生产环境运行效果也达不到理想。
想去修改,遇到下面的问题:
一、由于生产环境是运行在linux服务上的,在华为HD Insight大数据平台上,在开发机不知怎样调试。
解决方式:后来发现其实在idea是可以远程调试的:
- 打开工程,在菜单栏中选择“Run
> Edit Configurations”。
- 在弹出的配置窗口中用鼠标左键单击左上角的号,在下拉菜单中选择Remote,如图1所示。
图1
选择Remote
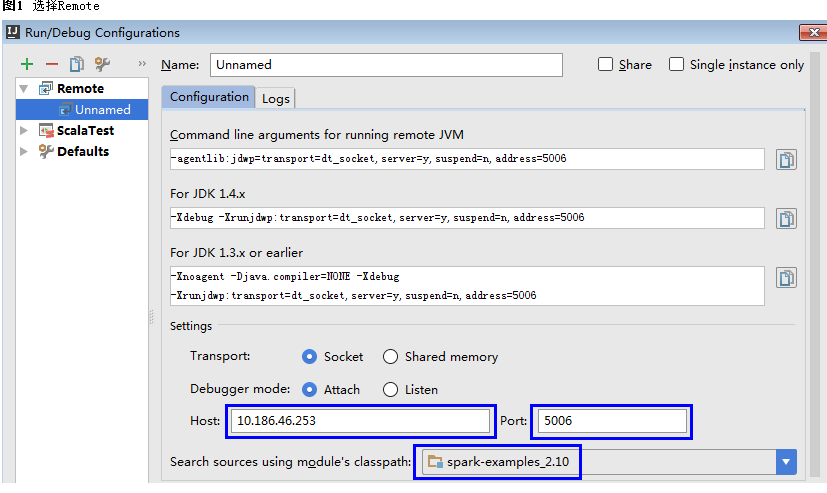
3. 选择对应要调试的源码模块路径,并配置远端调试参数Host和Port,如图2所示。
其中Host为Spark运行机器IP地址,Port为调试的端口号(确保该端口在运行机器上没被占用)。
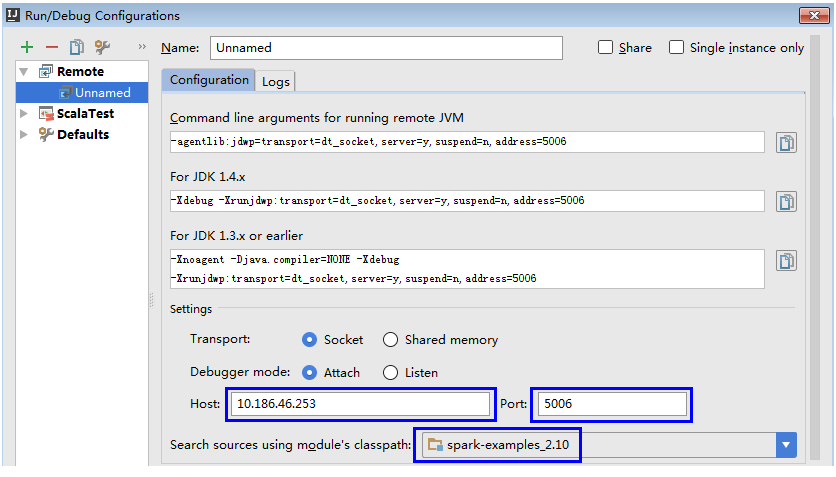
说明: 当改变Port端口号时,For JDK1.4.x对应的调试命令也跟着改变,比如Port设置为5006,对应调试命令会变更为-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5006,这个调试命令在启动Spark程序时要用到。
4.执行以下命令,远端启动Spark运行SparkPi。 ./spark-submit –master yarn-client –driver-java-options “-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5006” –class org.apache.spark.examples.SparkPi /opt/FI-Client/Spark2x/spark/examples/jars/spark-examples_2.11-2.1.0.jar 用户调试时需要把–class和jar包换成自己的程序,-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=y,address=5006需要换成3获取到的For JDK1.4.x对应的调试命令。

5.设置调试断点。 在IDEA代码编辑窗口左侧空白处单击鼠标左键设置相应代码行断点,如图4所示,在SparkPi.scala的29行设置断点。
6.启动调试。 在IDEA菜单栏中选择“Run > Debug ‘Unnamed’”开启调试窗口,接着开始SparkPi的调试,比如单步调试、查看调用栈、跟踪变量值等,如图5所示。
二、在spark executor执行的,如果看调试结果?
解决方式是在相应的rdd加上collect()方法,把结果传送到driver来看