随着时间的推移,人工智能的进步使机器变得越来越聪明,以至于它们学会了利用自己的训练和知识做出基于逻辑的决策,而几乎不需要人工干预。
目录
围绕 GPT-3 的议论
人类与 GPT-3 写作
GPT 3:它对 SEO 和内容营销的影响
关键要点
最后的话
常见问题
AI(人工智能)引人入胜且充满未来感,但埃隆·马斯克和比尔·盖茨等科技巨头以及斯蒂芬·霍金斯等科学家都表示他们对 AI 越来越谨慎。 不可否认,通过促进自动化,人工智能生成的内容在很多方面让日常生活变得更轻松,但在专业方面,工作自动化加剧了人们对被机器人取代的恐惧。
随着时间的推移,人工智能的进步使机器变得更加智能,以至于它们学会了利用自己的训练和知识做出基于逻辑的决策,而几乎不需要人工干预。 因此,它不仅对重复性的体力工作构成威胁,甚至对那些需要学习和决策的工作也构成威胁。
其中一项工作是内容营销人员或作家,他们投入逻辑思维、创造力和研究来为读者创造相关的内容(文本)。 但似乎,随着 Generative Pre-Trained Transformer Version 3 (GPT-3) 和其他自动化内容编写技术的出现,AI 可以以更快的速度生成类似人类的文本。 因此,内容营销人员了解 GPT-3 内容生成器将如何影响内容营销和搜索引擎优化 (SEO) 的未来至关重要。
围绕 GPT-3 的议论
如果您专业从事内容营销、数字营销机构、作家或 SEO 专家,那么您现在一定已经听说过 GPT-3 文案写作的嗡嗡声。 在讨论它对 SEO 和内容营销的影响之前,让我们从技术上了解一下 GPT-3 内容生成器。
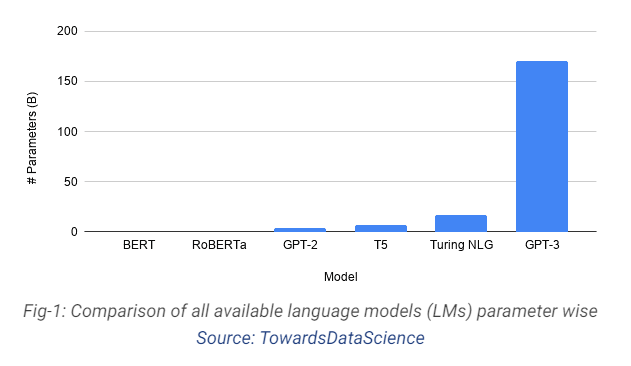
GPT-3 由总部位于旧金山的人工智能研究实验室 OpenAI 推出,是一种可以通过处理示例进行学习的深度神经网络。 它可用作自然语言处理 (NLP) 系统的自回归语言模型。 简单来说,GPT-3 是一种基于 AI 的预训练语言模型,可以自动生成文本。 这不是同类中的第一个,因为我们已经有了微软的语言模型、Turing NLG、NVIDIA 的 Megatron 和 GPT-2(GPT-3 的直接前身)。
但为什么 GPT-3 SEO 会产生如此大的炒作? 这是因为 GPT-3 文案自动编写的内容质量非常高,很难将其与真实作者编写的文本区分开来。
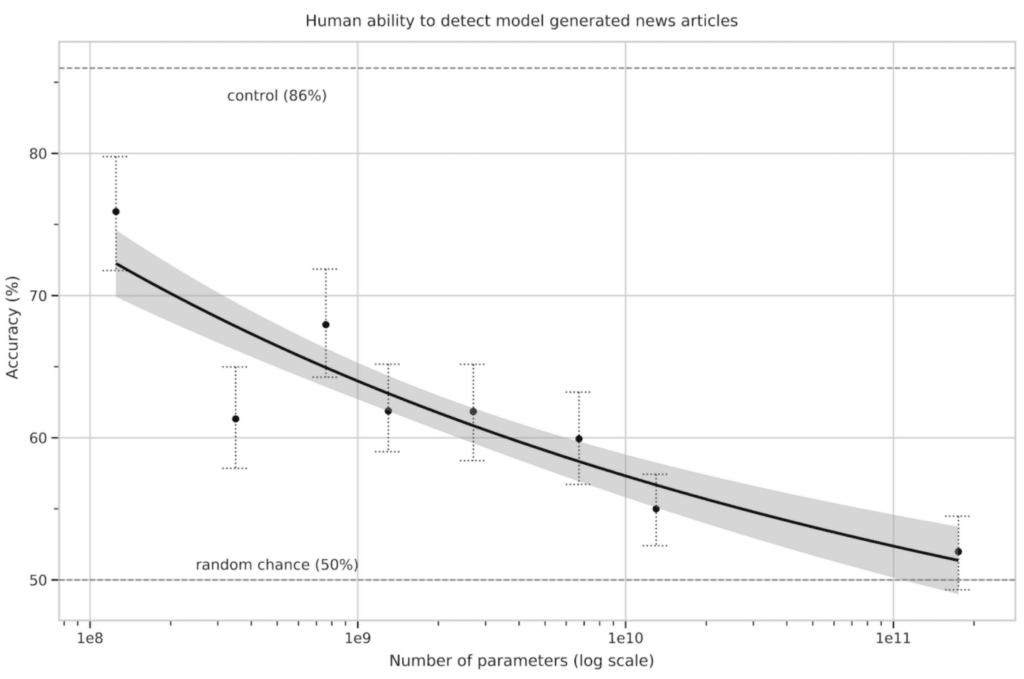
人类与 GPT-3 写作对比
2020 年 8 月,VWO 对 GPT-3 生成的文本与人工编写的文本进行了 A/B 测试。 450 个品牌中共有 18 个入围品牌参与,并使用 GPT-3 API 生成各种语言的副本以供测试。 根据 VWO,参与者对 AI 编写的内容所提供的语言准确性非常满意。
在几秒钟内,GPT-3 内容生成器就可以像人类一样写出令人信服的内容。 它可以写任何主题、任何风格或任何语气。 以下是用户发布的 GPT-3 生成内容示例。
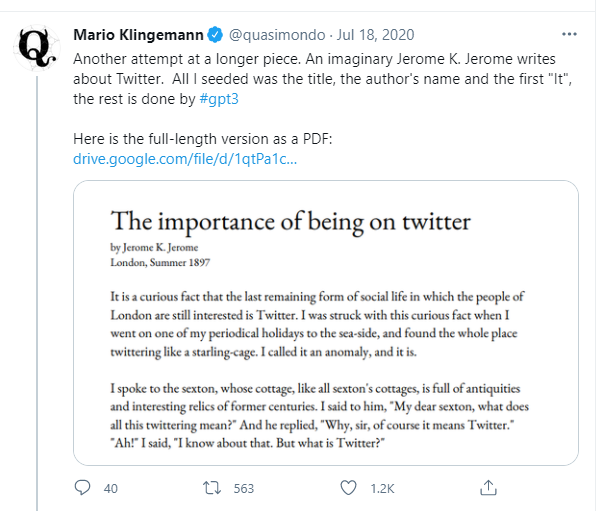
想象一下,一位作家为了获得某个学科或主题的知识而投入研究的时间; 与他竞争的是 GPT-3 SEO 编写的自动化内容。 它经过海量千兆字节的文本数据训练,实时拥有整个互联网的集体智慧。
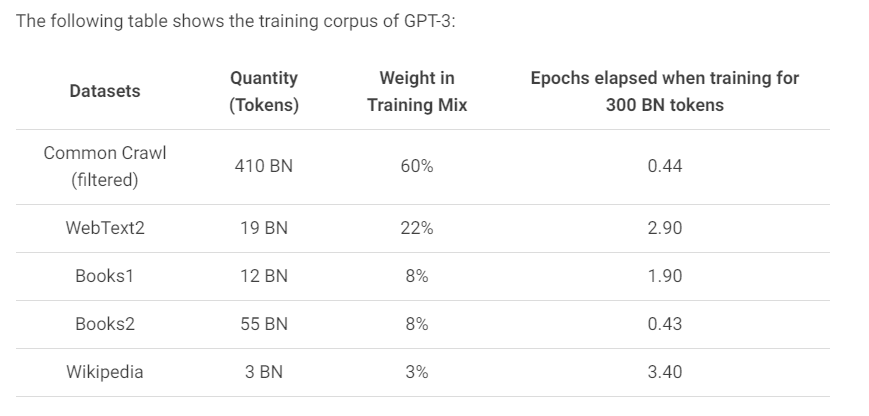
与其他语言模型相比,GPT-3 内容生成器如此特别的原因在于其 1750 亿个参数的容量。
GPT-3 能够进行称为“元学习”的事情,这使其成为与任务无关的模型。 因此,它可以在不同平台上执行多项 NLP 任务,无需或只需极少的微调(额外训练)。
Gmail 完成你的电子邮件句子,这也是人工智能,但它是“狭义人工智能”,这意味着它只接受特定任务的训练,不会处理其他任何事情。 Siri、Alexa 和 Cortana 都由狭义人工智能提供支持。
但作为一个任务不可知论者,GPT-3 内容生成器可以展示通用智能的一些特性。 因此,即使没有对特定任务进行手动工程,它也可以在一系列自然语言处理任务中实现类似人类的效率和准确性,例如语言翻译、文本分类、情感提取、新闻文章生成、撰写博客、创建社交媒体帖子、 生成推文、释义、创建博客主题、问答系统和角色对话。 它甚至可以生成 HTML 代码。 GPT-3 的写作速度是人类作家的 500 倍,它对语法和拼写的掌握无可挑剔。 它产生出色的语法并具有广泛的词汇量。
GPT 3:它对 SEO 和内容营销的影响
GPT-3 内容生成器可以自动生成文本,但这对内容营销意味着什么? 这是否意味着从 SEO 的角度来看,内容营销专业人士将能够通过 GPT-3 自动化内容节省资金? 这是否意味着内容作者的工作将会过时? 那么搜索引擎算法呢? 他们会接受 GPT-3 内容,还是会被列为黑帽 SEO?
GPT-3 文案不能取代注重质量和读者参与度的内容,因为 GPT-3 也有局限性,即它不能像人脑一样思考或变得有创造力。 它通过消化庞大的语言内容数据库进行学习,然后利用其通过评估先前单词来预测下一个单词的能力来编写新的合成内容。 因此,它可能会创建与主题相关的内容,但有时它可能完全没有头脑。
GPT-3 可以淘汰低质量或低成本的内容工厂
GPT-3 内容可以胜过内容工厂出售的低成本和低质量的内容,这些内容可读性强,但无法提高社交媒体份额或吸引反向链接。 在创建低层文章时,GPT-3 内容会更可靠,因为它可以更好地包含来自可靠来源的特定主题信息。 GPT-3 内容生成器在未来将继续变得更加实惠,当这种情况发生时,它将迫使内容工厂倒闭。
GPT-3 擅长创建短期内容,是改写、主题优化、摘要等目的的智能工具。但对于长篇事实内容,它就迷失了方向。
GPT-3 内容会排名吗?
使用 GPT-3 SEO 工具,SEO 从业者可以通过投入更少的时间和金钱来访问大量的博客和文章。 但他们能否将这些自动化内容片段用于 SEO 实践,或者像谷歌这样的搜索引擎会更新他们的算法来检测 AI 生成的内容并对其进行惩罚?
由于其能够创建大量博客点,GPT-3 SEO 面临成为黑帽 SEO 策略的诱人工具的风险,这反过来可能导致前所未有的互联网垃圾邮件。
谷歌作为搜索引擎的成功在于其将用户与有用内容联系起来的能力,而且它不会在这一点上妥协。 谷歌声称,对于其算法,对内容进行排名的唯一标准是它为用户增加了多少实际价值。 不管是人工智能编写的还是人工编写的; 如果内容用陈旧和重复的信息向互联网发送垃圾邮件,它就不会获得排名。
GPT-3:内容营销人员如何从中受益?
注重质量的内容营销人员不会在这里用黑帽 SEO 或低质量文章向互联网发送垃圾邮件。 他们已经避免了此类内容,并专注于能够:
与读者联系
提高品牌知名度
增加网站和登陆页面的自然流量
促进潜在客户的产生和转化
在社交媒体上分享
吸引更多观众
GPT-3 文案可以帮助内容营销人员实现这些目标吗? GPT-3 内容生成器可能并不总是能够编写概念上原创的、高质量的、合乎逻辑的和更长的内容,至少在这个时间点上是这样。 但它的 AI 可以提供很多功能,可以通过增强作家的构思能力来增强作家的潜力。 例如,它可以通过为标题、产品描述、CTA 按钮等生成建议来支持作者的构思。
内容写作本身就是一个艰难的过程。 这不仅仅是写一些语法正确的句子。 专业作家需要弄清楚要写什么,如何使它更具吸引力,如何使其以解决方案为导向或流行等等。 但是相当多的时间花在了重新措辞、主题优化、编写 SEO 元描述、谷歌广告文案脚注、作者描述、产品描述等任务上。
GPT-3 SEO 工具可以自动化这些类型的写作,以方便作者,并让他或她有更多时间专注于需要人类创造力、勤奋、研究和准备的写作方面。
例如,Peppertype.ai 是一种基于 GPT-3 的内容创建工具,旨在使创作者的构思过程相对容易一些。 使用该平台,作家或内容营销人员可以在几秒钟内获得 AI 制作的简短内容片段,例如社交媒体帖子标题、推文、电子商务产品描述、SEO 元描述、Facebook 广告、博客创意、时事通讯、播客 和营销理念。 只需一次输入,它就可以建议 15 个备选博客创意或推文创意。 因此,作为 GPT-3 工具的 pepper.ai 对内容开发人员来说是一个很大的推动力,因为它可以帮助他们节省时间,做更有意义的工作,并提出更好的文章。
关键要点
GPT-3(Generative Pre-trained Transformer)是一种使用深度学习生成文本的语言模型。
GPT-3 内容生成器由 Elon Musk 的 Open AI 于 2020 年 6 月创建。
Peppertype.ai 等许多工具都使用 GPT-3 SEO 集成功能来生成内容。
GPT-3 内容生成器可以在不同平台上执行多个 NLP 任务,无需或只需极少的微调(额外训练)。
GPT-3 内容生成器可以胜过低质量机构生成的低质量、关键字填充的内容。
GPT-3 文案写作也是可能的,因为它生成的文本几乎与人类编写的文本相似。 它使用培训分析,因此可以提供有关用户的信息以生成内容。
GPT-3 内容生成器或任何 AI 生成的内容最适合创建小标题、CTA、标题等。 GPT-3 还不能用来创建高质量的长篇内容。
GPT-3 内容或任何人工智能生成的内容无法与人类书面内容竞争,因为有时它没有意义。
GPT-3 将为 SEO 和数字营销人员提供一个新的搜索引擎市场,具有强大的 NLP。
Google 根据内容的相关性对内容进行排名。 因此,由 GPT-3 SEO 串在一起的一堆词不会像有意义的内容那样排名。
GPT-3 内容生成器将改变未来数字营销的面貌。
GPT-3 文案写作不会完全取代人类作家。 这会帮助他们。
最后的话
GPT-3 内容生成器是在推出其前身 GPT-2 一年后推出的。 仅在一年内,其制造商就将其容量从 15 亿个参数更新为高达 1750 亿个参数。 这就是 GPT 语言模型快速发展的方式。
未来,这些模型将变得更加复杂,并将开发出更像人类的 NLP 能力。 随着演变的每个阶段,它将继续影响内容营销和实践它的人。 保持领先地位的唯一方法是根据 GPT 和其他此类技术带来的变化进行调整和发展。 如果内容营销人员学习如何释放其潜力,该工具可以成为对内容营销人员的强大、增强的支持。
常见问题
谁可以使用 GPT-3?
Elon Musk 的 Open AI 于 2020 年 6 月发布了 GPT-3 内容生成器。它已经发布了有限的 beta 容量。 开发人员在候补名单上注册以使用其功能。 世界各地的许多开发人员已经认识到 GPT-3 文案的潜力,候补名单已被淘汰。 Open AI 于 2021 年 11 月宣布将立即提供给开发者使用。 但是,有一些条件。 只有某些国家可以使用它。 来自古巴、伊朗和俄罗斯的开发人员将无法使用这种完全集成的 GPT-3 SEO 的功能。
GPT-3有什么用?
GPT-3 内容生成器,顾名思义,用于生成逼真的自动化内容,就像真人制作的那样。 诚然,创造力无法喂给机器。 但是,通过用户培训分析,GPT-3 SEO 结合了搜索引擎优化。 有关目标受众的信息被输入其中,以生成近乎完美的副本。 它已经产生了文章、诗歌、新闻报道、故事、对话等等。
训练GPT-3需要多长时间?
大型机器学习模型,如训练 GPT-3 内容生成器所需的模型,需要巨大的计算能力(数百 exaflops)并减少内存占用。 这些模型包含大型嵌入表。 单个 GPU 是不够的。 如果他们的任务是运行像 BERT 或 GPT-3 这样的数十亿参数语言模型,它就会崩溃。 模型并行技术用于跨多个 GPU 拆分参数。 然而,它们非常昂贵、难以使用且难以扩展。 使用 8 个 V100 GPU 训练 1750 亿个参数的 GPT-3 内容生成器需要 36 年。
GPT-3训练了哪些数据?
GPT-3 SEO 拥有 1750 亿个参数,是最大的内容生成器语言学习模型。 它使用来自不同数据集的 45TB 文本数据进行训练。 模型本身没有信息。 它不是为存储事实而设计的。 GPT-3 内容生成器的唯一目的是预测下一个单词或句子序列。
GPT-2 和 GPT-3 有什么区别?
GPT-2 内容生成器无法生成音乐和广泛的故事。 GPT-3 可能是迄今为止最大的语言学习模型。 GPT-3 SEO 非常擅长生成讲故事的内容。 它还可以总结文本、翻译语言、生成计算机代码、撰写论文、回答问题等等。 但是,GPT-3 只擅长预测下一个句子序列。 它不能存储信息。